Translation
Elizabeth Rebarchik
Objective 4: Describe translation: how RNA is made into protein.
Molecular Biology Objective 4 Video Lecture
Protein Synthesis Organelles
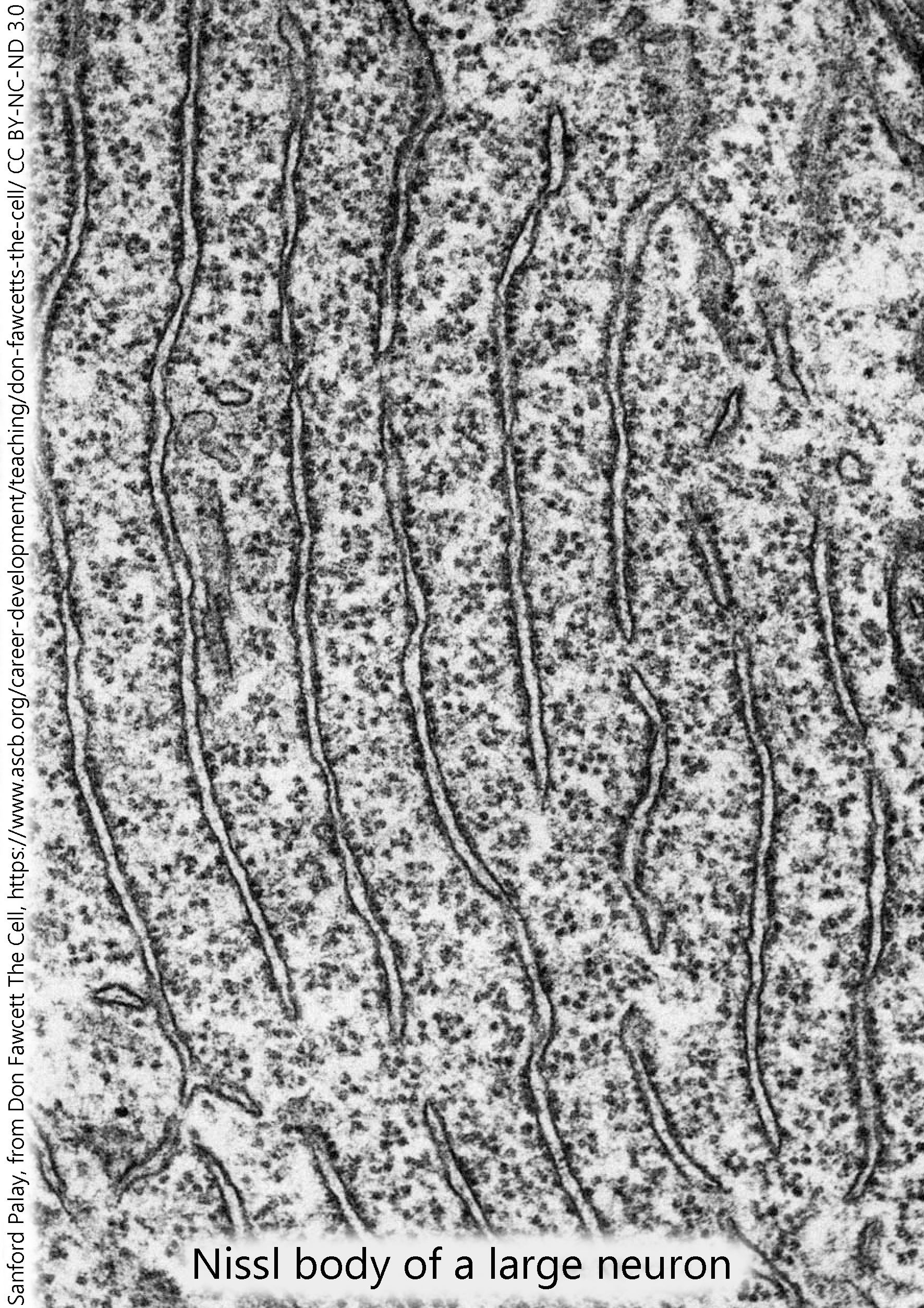
The machinery of protein synthesis was first seen as Nissl substance, the negatively-charged RNA and other nucleic acids that bind to positively-charged cresyl violet dye.
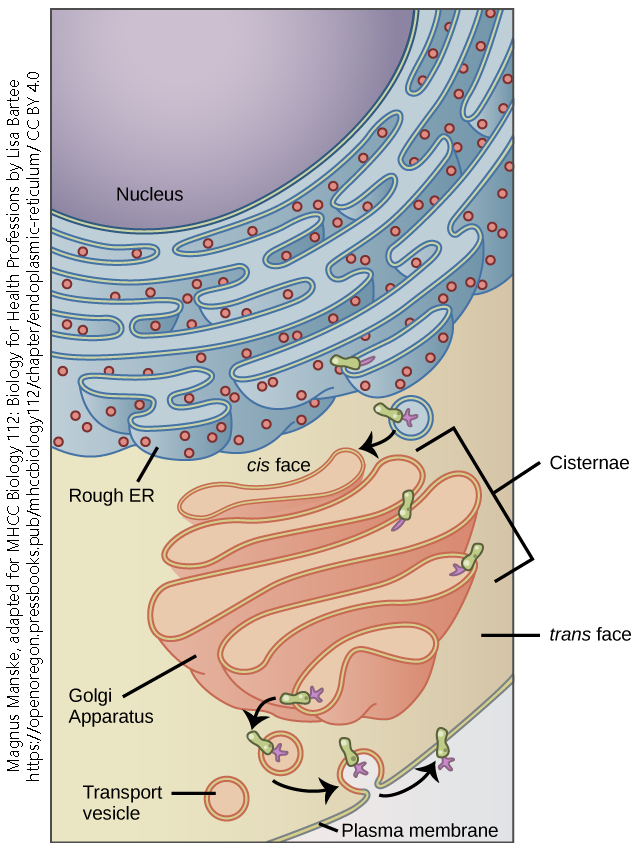 Later, biochemists found that structures called ribosomes are responsible for protein synthesis. The ribosome is a macromolecular machine which is assembled from RNA “parts” as well as protein “parts”.
Later, biochemists found that structures called ribosomes are responsible for protein synthesis. The ribosome is a macromolecular machine which is assembled from RNA “parts” as well as protein “parts”.
 Under the electron microscope, ribosomes are seen as dark, electron-dense spots. They can be found alone, floating in the cytoplasm (free ribosomes) or associated with the endomembrane system (rough endoplasmic reticulum).
Under the electron microscope, ribosomes are seen as dark, electron-dense spots. They can be found alone, floating in the cytoplasm (free ribosomes) or associated with the endomembrane system (rough endoplasmic reticulum).
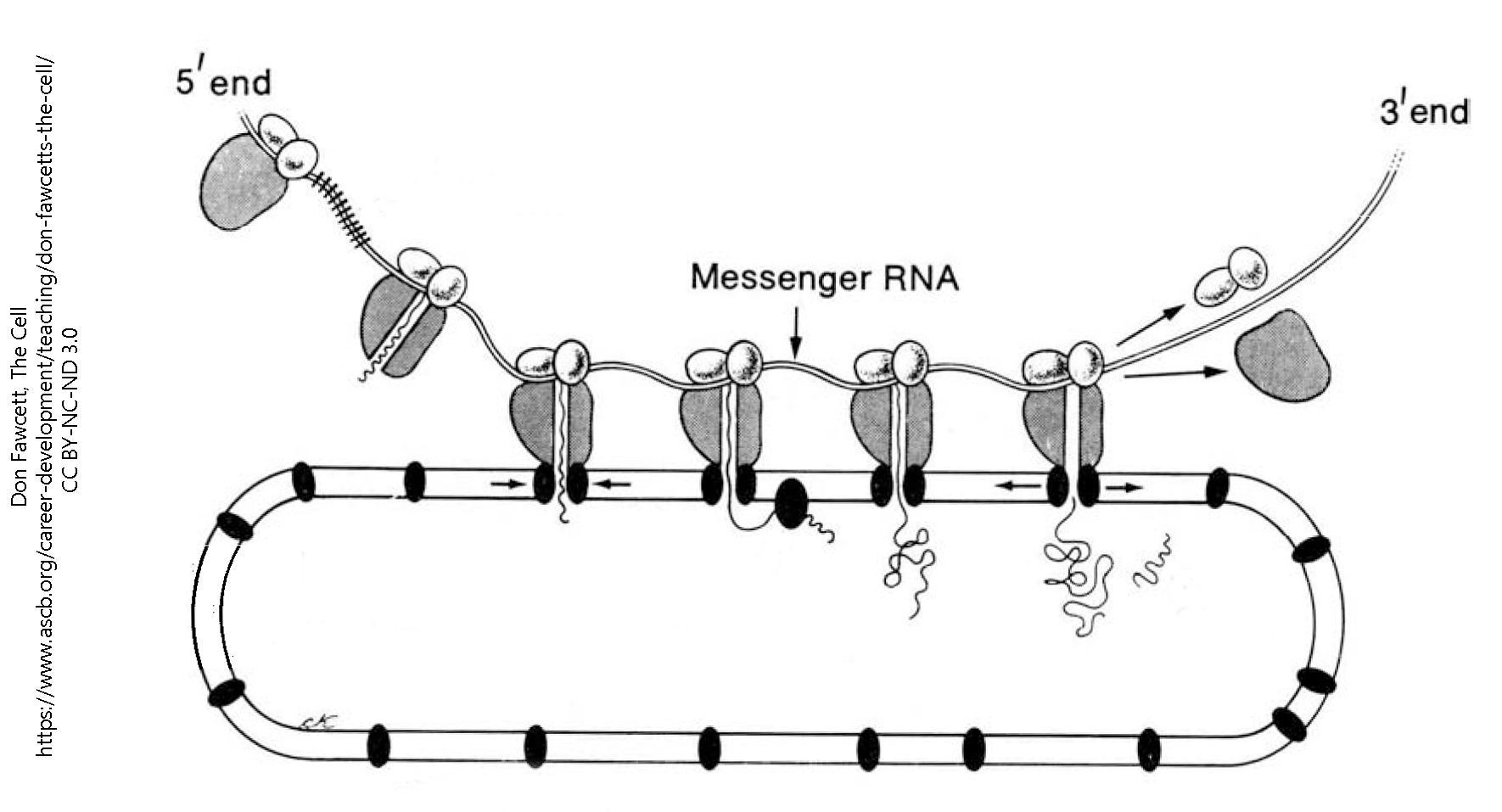 Electron microscopists immediately grasped that the rough endoplasmic reticulum was a large part of the Nissl substance which had been seen by light microscopists, and that ribosomes were the site of protein synthesis. They accomplish this by sliding along a threadlike messenger RNA molecule, from 5′ to 3′, assembling amino acids into a protein as they go.
Electron microscopists immediately grasped that the rough endoplasmic reticulum was a large part of the Nissl substance which had been seen by light microscopists, and that ribosomes were the site of protein synthesis. They accomplish this by sliding along a threadlike messenger RNA molecule, from 5′ to 3′, assembling amino acids into a protein as they go.
Codons Carry the Genetic Code; Alterations in the Code Lead to Alterations in Proteins
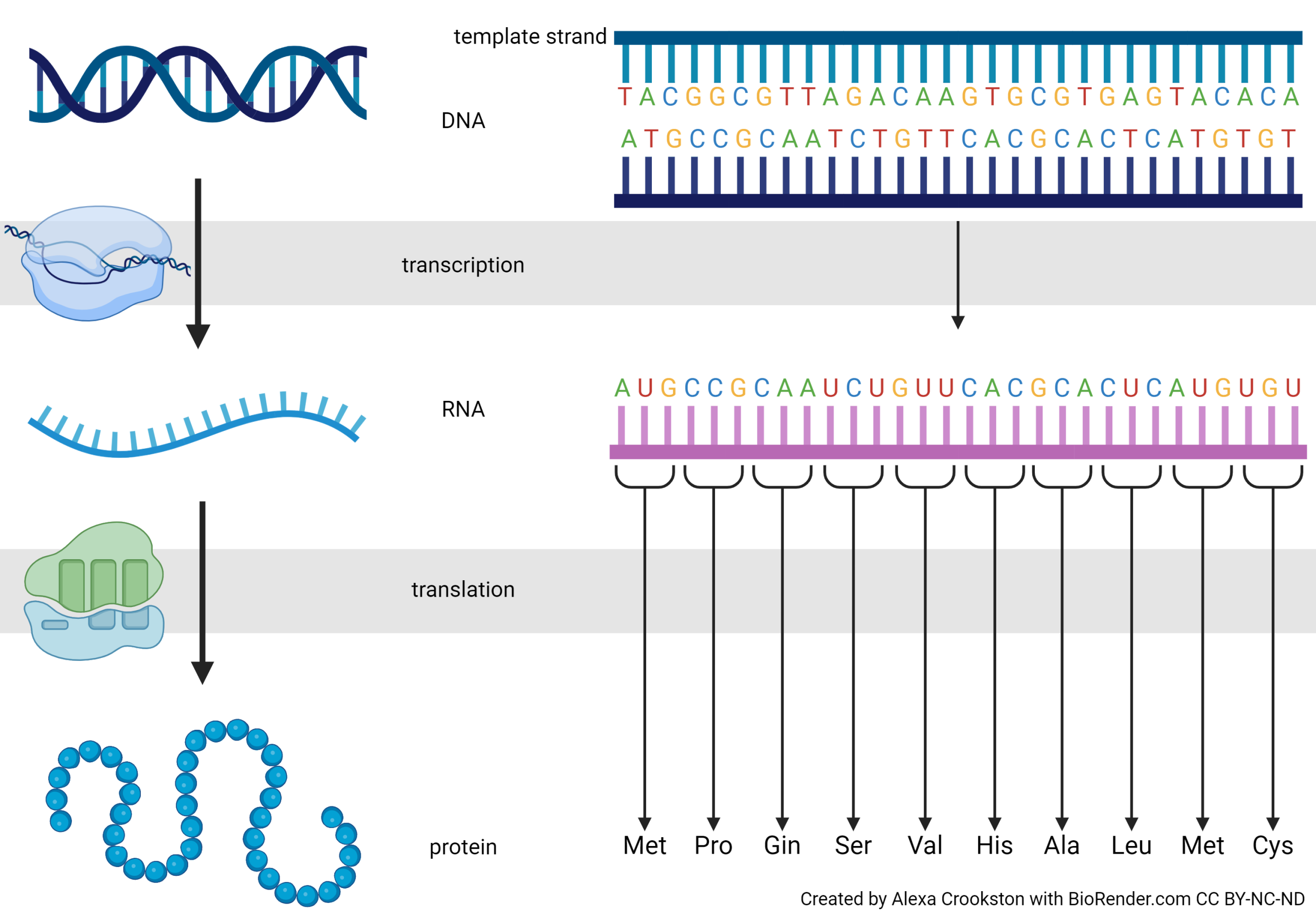
In this image we see the precise expression of the Central Dogma. Notice we are changing the DNA language to RNA language (transcription). Each thymine (T) becomes a uracil (U) and the RNA strand is built on a ribonucleophosphate backbone, but otherwise the language is unchanged. Translation, as the name implies, converts the nucleic acid language to a different language: the primary sequence of amino acids.
Why is the codon three DNA or RNA bases, and not one? Or two? Or four?
There are four DNA bases: A, C, G, and T. There are also four RNA bases: A, C, G, and U. Four bases can code for four amino acids: 1. A 2. C 3. G 4. U. Mathematically, we say
41 = 4
How many different amino acids could we code for with two of the four bases? The possibilities are 1. AA, 2. AC, 3. AG, 4. AU, 5. CA, 6. CC, 7. CG, 8. CU, 9. GA, 10. GC, 11. GG, 12. GU, 13. UA, 14. UC, 15. UG, 16. UU
42 =16
That’s still short of where we need to be for 20 amino acids.
I won’t list all the possibilities for four bases taken in groups of three, but I hope you’ll see that the number is
43 =64
(If not, count the possibilities in the codon table shown below.) That’s enough to code for 20 amino acids, with some information left over. So, four bases in groups of three is how we do it. Nirenberg and his lab figured out the probability of each combination of three bases in mixtures with different proportions of A, C, G, and U, and then matched that to the proportion of amino acids in artificial proteins made by ribosomes exposed to those artificial mRNA sequences. In this way, they found that AUG codes for methionine, CCG for proline, CAA for glutamine, and so forth.
Because these are 64 combinations of bases for 20 amino acids, the genetic code is called degenerate. In information theory terms, that means there are more possible codes than there are amino acids to encode. That lets us use multiple combinations to code for the same amino acid. For example, there are four codons for proline, two for histidine, one for tryptophan, and so forth.
It was still up to scientists to figure out which three-letter combinations correspond to which amino acids. For this, we needed a Rosetta Stone.

The Rosetta Stone was a carved rock that had both Greek and Egyptian hieroglyphics on it. There was no “hieroglyphic dictionary” that survived to the modern period so the Rosetta Stone was the only way we could translate hieroglyphs. Archeologists knew Ancient Greek, so they used the Rosetta Stone to convert hieroglyphs to Ancient Greek, and from there to French and other modern languages.
Some clever science in the 1960s provided this Rosetta Stone. Nirenberg made artificial RNAs that contained different proportions of A, C, G, and U. The easy ones were artificial RNAs made up of all one letter: AAAAAAA…; CCCCCCC…; and so forth. By making mixtures of (say) 10% A and 90% C, they could predict how many AAA, AAC, ACA, ACC, CAA, CAC, CCA, and CCC codons there would be. They matched those to the proportion of different amino acids they found when they mixed these artificial RNA molecules with ribosomes.
A codon table is reproduced here. This is the molecular biologist’s Rosetta Stone, the mechanism by which an RNA sequence can be turned into a protein sequence.
No one memorizes the codon table, and we don’t expect our students to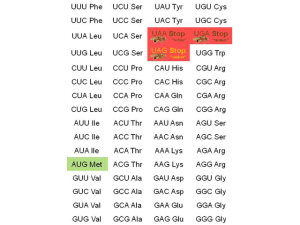 do it, either. Rather, you need to be able to use the codon table and understand how it works.
do it, either. Rather, you need to be able to use the codon table and understand how it works.
Four codons deserve special mention. Remember that we need a starting place, a stopping place, and codes for the amino acids in between.
Protein synthesis always starts with the codon AUG, which codes for the amino acid methionine. For that reason, AUG is termed the start codon. If the final protein does not need methionine in this position, then it is cleaved away after the protein chain is made.
Protein synthesis ends with either UAA, UAG, or UGA. These are called the stop codons.
Oddly, each has its own name: UAA is called ochre; UGA is called umber; and UAG is called amber. It sounds like names from a bad spy movie. In reality, the names are fruit fly (Drosophila) eye colors. Fruit flies were an important part of genetic research for many years, and mutations to a UAA (where it shouldn’t be) produced flies with ochre eyes. Other eye colors were formed by mutations to the other stop codons.
RNA is translated into protein. Translation changes the language. In this case, translation changes the A, C, G, U language to the amino acid language. Four bases are translated into 20 amino acids.
Now we can see the special roles played by each type of RNA:
- Messenger RNA carries the coded message from the nucleus to the ribosome
- The ribosome is made up of ribosomal RNA and proteins. Together, rRNA and protein form ribosomes.
- The factory is supplied with amino acids for protein synthesis by transfer RNA, the “trucks” that bring the correct amino acid for the next “word” in the genetic code. Each tRNA has a unique anticodon (a set of three ribonucleotides which will bind to the mRNA). This anticodon is paired with a specific amino acid which binds to an acceptor arm. For example, the anticodon 5’–GGG–3’ (complementary to the codon 5’–CCC–3’, as listed in the codon table) is found on a tRNA that is carrying the amino acid proline. These pairings are the basis for the genetic code.
Ribosomes Are Macromolecular Machines That Make Proteins
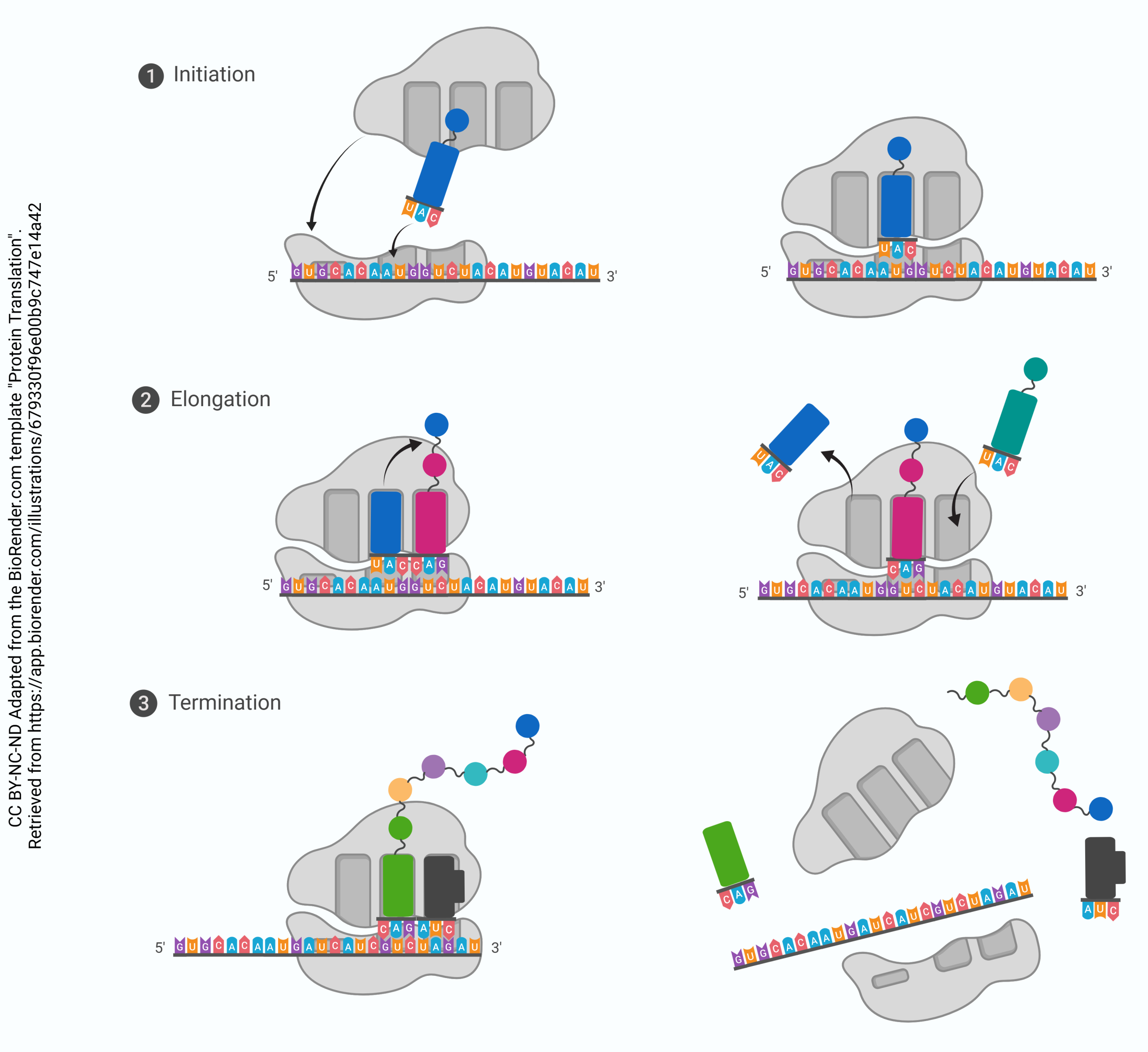
Each tRNA carrying an amino acid cargo docks in the A site. It then moves to the P site, where it picks up the growing polypeptide (newly-born or nascent protein) chain. It then transfers the protein chain to the next tRNA as it moves to the P site, and is released from the E site. When the ribosome encounters a stop codon (UAA, UGA, or UAG), the entire ribosome falls apart and translation stops.
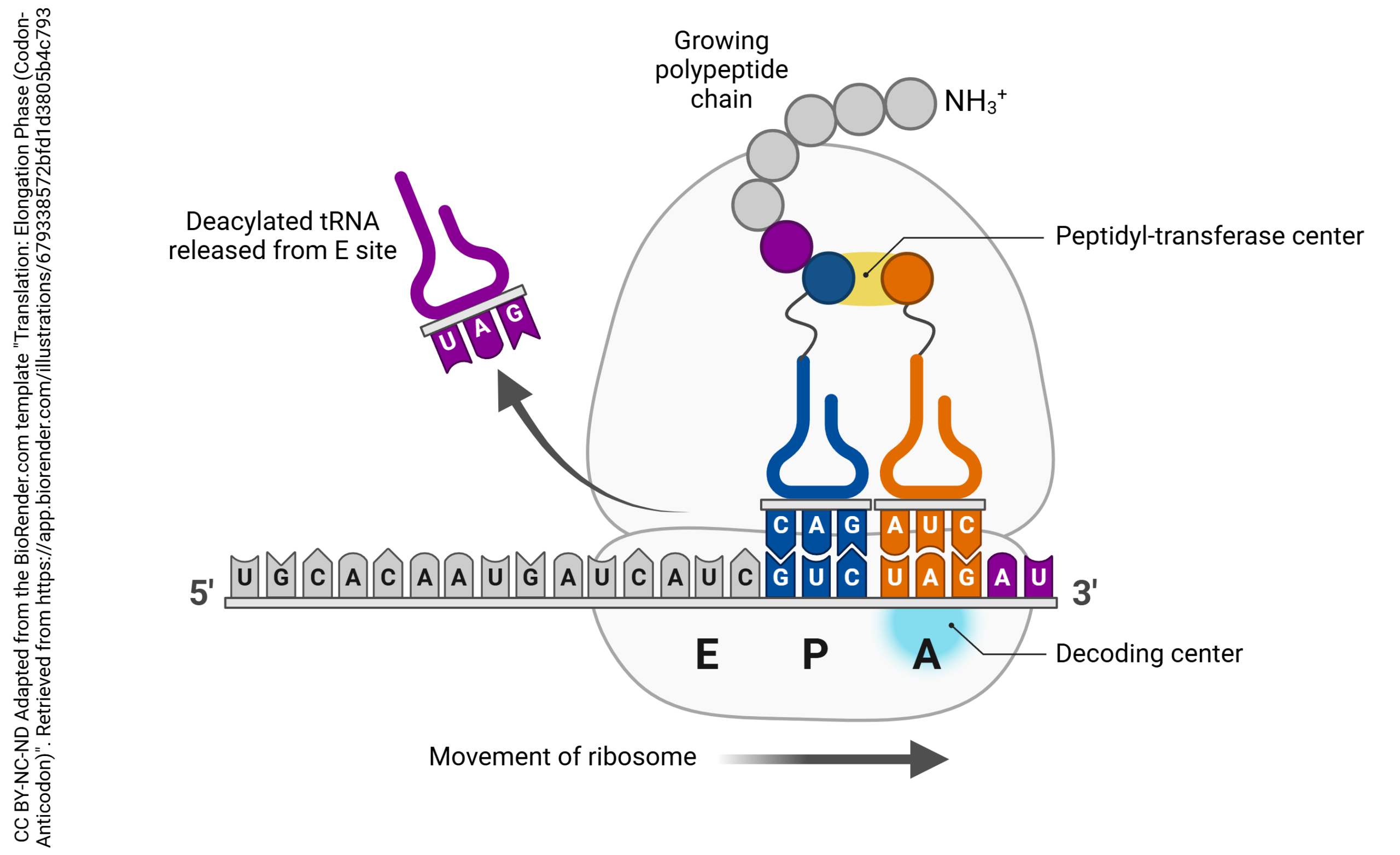
The large subunit of the ribosome has three special sites, termed “A”, “P”, and “E”.
The tRNA which carries an amino acid is called by the rather fancy name aminoacyl-tRNA. That’s what sits in the A site. Think of it as a “truck” (transfer RNA) that is still carrying an amino acid “cargo”.
The tRNA which holds onto the growing polypeptide chain is called by the name peptidyl-tRNA. That’s what sits in the P site.
The tRNA which is not bound to anything is obligated to exit from the ribosome. That’s what happens at the E site.
Stepwise Process for Translation:
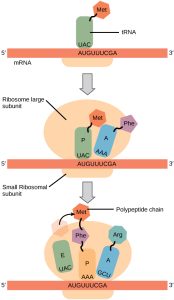
Step 1. mRNA attaches to the “P” position of the ribosome. 5’–AUG–3’ is always the start codon. Its complementary anticodon is 5’–CAU–3’. The tRNA with the anticodon CAU always carries a methionine.
When the AUG start signal is detected on the mRNA, Met-tRNA binds there.
Step 2. The binding of Met-tRNA triggers assembly of the small (40S) and large (60S) ribosomal subunits into a functional macromolecular machine at the site of tRNA binding. The large (60S) ribosomal subunit always assembles so that the Met-tRNA is enveloped in the P site. The A site is empty at this point.
Step 3. Now, the ribosome is assembled and ready to begin synthesis of the protein strand. The next codon is read (for example, AAU, which codes for asparagine or Asn). The Asn-tRNA nestles into the A site, next to the Met-tRNA which is still in the P site.
Step 4. In this step, the amino acids who find themselves snuggled together in the P and A sites decide they might as well form a peptide bond. When they do, the synthesis of protein has begun. The methionine is transferred to the Asn-tRNA and the tRNA which used to carry methionine is released to go get another one. This leaves the P site open.
Step 5. The Met-Asn-tRNA moves into the vacant P site as the ribosome ratchets three bases down (i.e., toward the 3’ end) the mRNA molecule. Now, the A site is empty. The next codon is (for example) 5’-UUA-3’. This codes for leucine, so the Leu-tRNA will be bound to the ribosome complex at that site.
Step 6. This process continues, and the polypeptide chain grows.
Step 7. The stop codon is reached. There is no tRNA for the stop codon; rather, the stop codon leaves the A site empty and the full-length protein is bound to the last tRNA at the P site. The ribosome disassembles, and the tRNA, protein, and ribosomal subunits all drift away from each other. The primary structure of the protein is now established.
Post-Translational Modification of Proteins
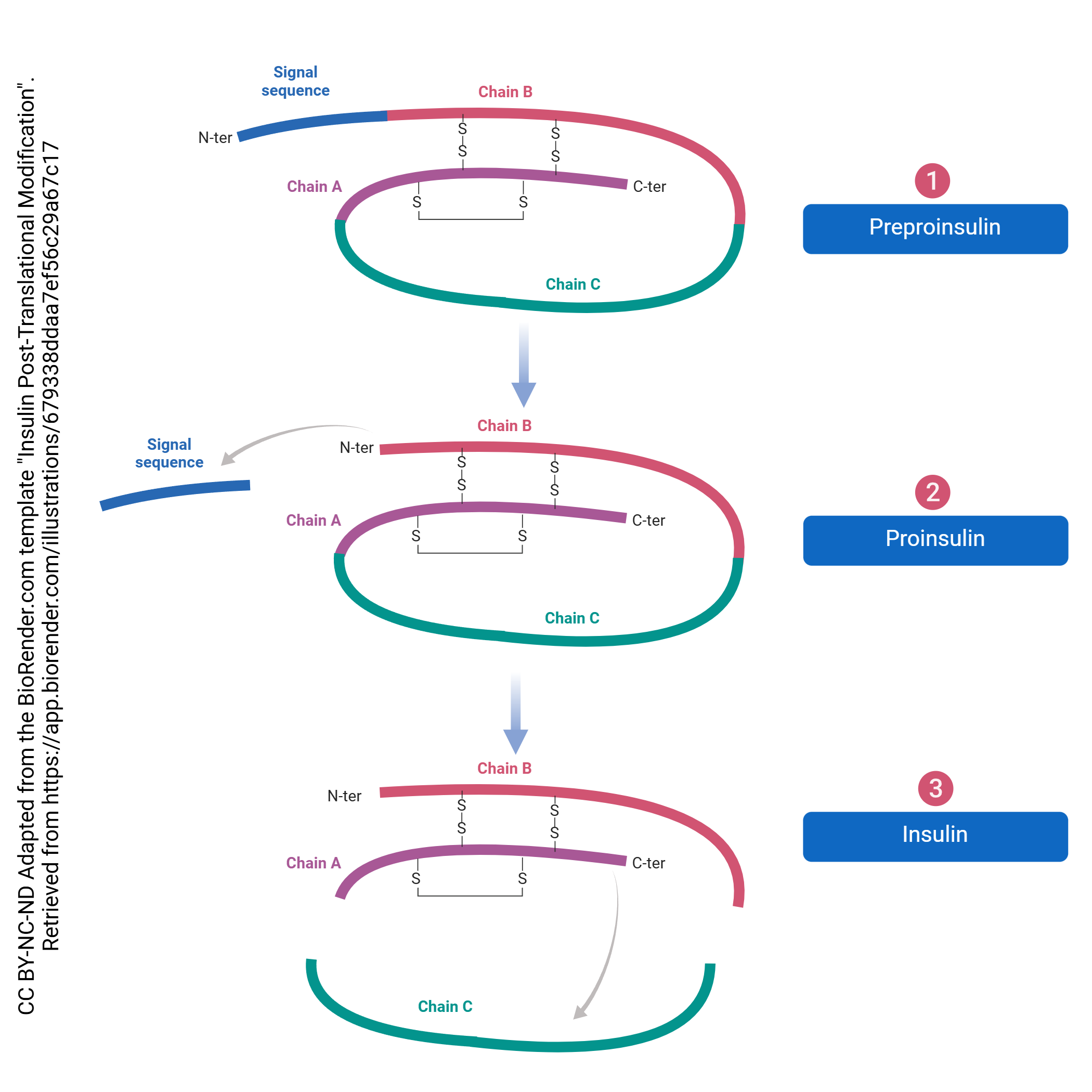
Just as there is processing of the pre-mRNA into the final mRNA, there is processing of the protein which must be done to create its final form. This processing begins in the RER and continues in the Golgi complex. For example, even though most proteins don’t start with methionine, all translation starts there. This is called post-translational processing because it happens after translation. The post-translational processing of insulin is shown here. It’s not important to know the details of this process for this specific signaling molecule, but rather get a sense of the general process that transforms the protein into its final, functional form.
Media Attributions
- Endomembrane system © Betts, J. Gordon; Young, Kelly A.; Wise, James A.; Johnson, Eddie; Poe, Brandon; Kruse, Dean H. Korol, Oksana; Johnson, Jody E.; Womble, Mark & DeSaix, Peter is licensed under a CC BY (Attribution) license
- Endoplasmic Reticulum © Sanford Palay is licensed under a CC BY-NC-ND (Attribution NonCommercial NoDerivatives) license
- Endoplasmic Reticulum © Don W. Fawcett is licensed under a All Rights Reserved license
- DNA to Proteins © Alexa Crookston is licensed under a CC BY-NC-ND (Attribution NonCommercial NoDerivatives) license
- Rosetta stone © Charles Tilford is licensed under a CC BY-NC-SA (Attribution NonCommercial ShareAlike) license
- Codon table © Jim Hutchins is licensed under a CC BY-SA (Attribution ShareAlike) license
- Protein Translation © BioRender adapted by Jim Hutchins is licensed under a CC BY-NC-ND (Attribution NonCommercial NoDerivatives) license
- Translation Elongation Phase (Codon-Anticodon) © Samara Ona adapted by Jim Hutchins is licensed under a CC BY-NC-ND (Attribution NonCommercial NoDerivatives) license
- Translation © Betts, J. Gordon; Young, Kelly A.; Wise, James A.; Johnson, Eddie; Poe, Brandon; Kruse, Dean H. Korol, Oksana; Johnson, Jody E.; Womble, Mark & DeSaix, Peter is licensed under a CC BY (Attribution) license
- Insulin Post Translational Modification © Qingyang Chen adapted by Jim Hutchins is licensed under a CC BY-NC-ND (Attribution NonCommercial NoDerivatives) license
