College of Humanities
34 Learning About Fan-Fiction Genres via Data Science
Tianye Dai; Anne Jamison; Kate Issacs; and Marina Kogan
Faculty Mentor: Anne Jamison (English, University of Utah)
Abstract
Determining how to categorize works of fiction into genres often leads to debates. Traditionally, when discussing genres, we think of categories such as Fantasy, Mystery, Romance, etc. This research explores genres within fan fiction by analyzing tags that describe the type of content in stories through a data science approach. We construct a network of popular generic tags from Archive of Our Own (AO3), a platform for sharing and reading fan fiction. Using community detection methods, we identify clusters of tags that frequently co-occur in the same story. Additionally, we build another network to examine the connections between these tag clusters. Exploring tags is a potential way of understanding how genres are organized in the fan-fiction community, which tends to be more complex and nuanced compared to traditional genres. This technology-driven method may reveal new genre forms distinct from conventional categories. Our findings provide insights into genre dynamics within this female/LGBTQIA+ centered community, uncovering patterns that warrant further exploration. These insights could be valuable for future researchers seeking to better understand fanf iction community behaviors.
Introduction
In this research, we examine genres in fan fiction through a data science approach. Previously, researchers on fan fiction have often focused on qualitative and literature-focused aspects of the subject. We aim to look at fan fiction from a newer perspective and on a larger scale, using a more quantitative method. We hope our findings will provide other fan-fiction researchers who employ qualitative methods some inspiration on what to focus on in the future.
Fan fiction is a type of story that features characters, settings, or plotlines from existing books, movies, TV shows, or other media. Archive of Our Own (AO3) is a non-profit website where fan-fiction lovers share and read fan fiction, and this is where our data comes from.
When speaking of genres, we typically think of very general terms such as Mystery, Fantasy, Romance, etc. It seems that genre may work in a very different way in fan fiction. People tag their stories to indicate the content and themes of their work, and these tags are much more specific and complex than the traditional genres we know. We’re exploring the relationship between tags by establishing a network to see which tags are closely linked together and the connections between tag groupings. Our findings provide insights into genre dynamics within this female/LGBTQIA+ centered community, uncovering patterns that warrant further exploration and may offer a new way of grouping artistic works into genres.
Methodology
We plan to create a network of the tags using NetworkX, conduct community detection analysis to find clusters of tags that are often used together in the same story, and then visualize the connections between tag groupings using Gephi. Imagine network as a map: Nodes are like cities on the map. In our case, each city represents a tag used in stories on AO3. Edges are like roads connecting the cities. Here, a road between two cities (tags) means that those two tags appear together in the same story. Every edge has a “weight.” The weight of an edge indicates the strength of the connection between two tags, similar to how well-traveled a road is. The more frequently two tags are used together in the same stories, the greater the weight. Once we have this map of tags, we’ll use a method to find clusters of tags that are frequently used together, similar to finding neighborhoods in a city where houses (tags) are closely packed together.
We started by collecting the top 1000 most popular tags from the database. Then, we filtered out tags that are not descriptive of content, such as tags that indicate relationships or fandoms. Then, we established a table of the edges by counting the total number of co-occurrences between every pairwise combination of the tags. Using the edge table, we created a graph, which indicates the relationships between tags through nodes and edges.
To identify clusters of tags that are often used together, we applied Greedy Modularity Maximization, a community detection method that begins with each node in its own grouping and repeatedly joins pairs of groupings that lead to the largest increase in modularity until no further increase is possible. We tried different parameters to apply this method and picked the one whose grouping makes the most sense to us. After this step, we have 55 tag communities, each having 1-56 tags.
We then visualized our findings to make them easier to analyze. Visualizing a network with 441 nodes can be too messy. Therefore, we grouped tags in a grouping together as a single node, gave each grouping a name according to the content of the tags, and created a graph with 55 nodes. We combined the edges into edges between tag groupings by calculating the sum of every pairwise combination of the tags in each grouping and then divided it by the number of combinations to normalize the edge weight. We filtered out edges with minor weight (those under 7000) for optimal visualization and then visualized the results in Gephi. When displaying the network, we chose the ‘Dual Circular Layout’ since it provides a relatively clearer visualization of our network and is able to display nodes with a higher degree in an inner circle. This makes it easier for us to identify groupings that are connected to most groupings.
Results & Insights
Tag Grouping Detection
We found several interesting tag groupings that the community detection method identified. One notable finding is that traditional genre tags are in a single grouping (e.g., Action, Adventure, Comedy, Drama, Fantasy, Mystery, Romance, etc.). This suggests that how the fan-fiction community classifies their stories in terms of content is different from how we traditionally divide works into genres. ‘Maleslash’ is also in this grouping, which is interesting to us; it is a relatively old-fashioned term that people used more in earlier years. Nowadays, people tend to use ‘M/M’ instead. This might show that people who tend to use traditional genre names in their tags are an older group in the fan-fiction community. There are some other interesting tag groupings we found: ‘Femslash’ is always grouped with short fics, and ‘Pregnancy’ is always grouped with ‘ABO’ tags. This graph shows the connections between 55 tag groupings, with each node representing one grouping.
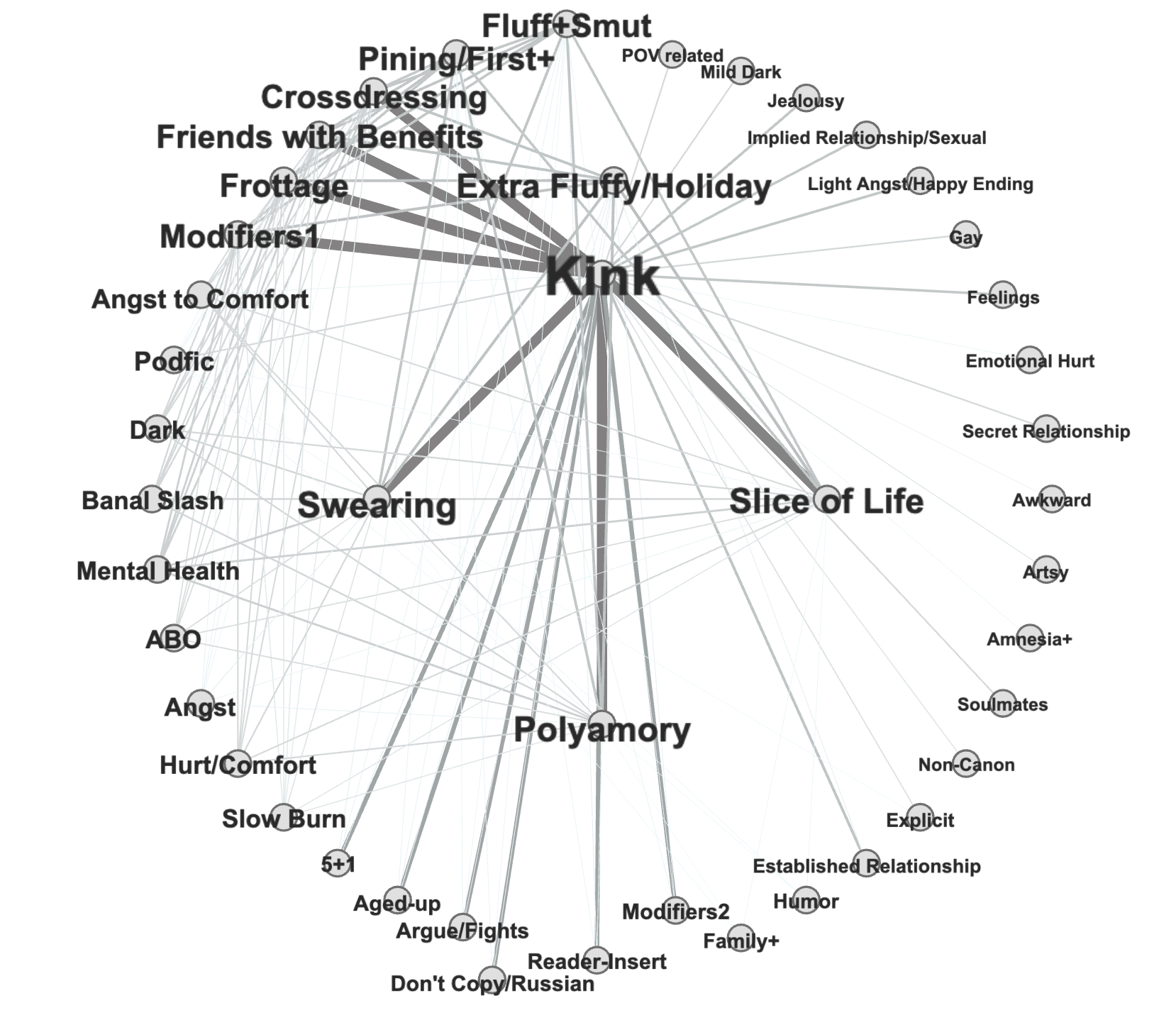
The nodes in the center are those with the highest degree, meaning they are connected to most other tag groupings at a high level. The bigger the name of the edge, the higher its degree. We could see that ‘Kink’ is the largest group, followed by ‘Swearing,’ ‘Polyamory,’ ‘Slice of Life,’ ‘Extra Fluffy/ Holiday,’ etc. The fact that fluff-related groupings are highly connected to other groups makes sense to us, given that ‘Fluff’ is the most popular generic tag and that people tend to like sweet and lighthearted elements. It is also not surprising that ‘Kink’ is the most popular community given that a significant portion of fan-fiction stories is about romantic relationships between characters
Fandom Network
Using a similar method, we established a network of fandom tags, with each fandom as a node and the number of authors who write in both fandoms as an edge. Then, we performed a similar community analysis on this network using Greedy Modularity Maximization. The top 200 fandoms were divided into 20 fandom groupings.
We could see signs of traditional genres in some of these groupings. For example, all anime-related fandoms are grouped together, musicals are grouped together, and Marvel movies are in a group. ‘Fantastic Beasts and Where to Find Them’ and Harry Potter are grouped together because they have the same background plots. All the bands such as ‘EXO’ and ‘5 Seconds of Summer’ are grouped together, and interestingly, ‘The Untamed’ is also in this group probably because the actor of this TV series was in a band.
We also observed several groupings that we can’t confidently account for. Here’s one example:
[‘Doctor Who’, ‘Hannibal (TV)’, ‘James Bond (Craig movies)’, ‘Merlin (TV)’, ‘Sherlock (TV)’, ‘Supernatural’]
This group makes a lot of intuitive sense to us and, we believe, to many people familiar with fan f iction. We might call this group something like the “smartest man in the room” group, given that most of them have a major male character superior to others in some aspects. If we try to group them into traditional genres, we’d notice they vary greatly, including Fantasy, Adventure, Thriller, Drama, Action, and Horror. However, they’re together in a group, and there are indeed people who like and write about them.
Findings like these are interesting to us and provide insights into a more systematic way of grouping works in terms of their content and theme.
Limitations & Future Work
Limitation of Methodology
There are limitations to our visualization method. When making tag groupings into one node and combining their edges, we found the average number of co-occurrences of every pairwise combination of the tags from the two group nodes. This might omit some strong connections between individual tags in two groupings since we’re looking at the average. And because of this, the connections of groupings with a large number of tags might be underestimated by our current network. This is a tradeoff we made: we decided to look at the data on a larger and more general scale to see the bigger trend.
Another limitation is that the parameters we set when running Greedy Modularity Maximization need further validation. When deciding the number of groups we want the method to divide our tags into (by setting the resolution value), we chose the parameter in a way that made the most reasonable grouping. For example, if 441 tags are divided into only two groups, we won’t get much from the results; and if there are too many groups with too many single tags, we might not be able to identify potential genres. The current grouping we have shows obvious signs of having similar content for each grouping, but future scientific validation of the parameters is needed to ensure our findings are reliable from a data science perspective.
Limitations of Data
The dataset we have is limited to dates prior to May 2020. This means we will not be able to catch trends after this date if any changes occur. We will work on gathering data after this date in the future, which should provide interesting insights, such as how the fan-fiction community responds to the pandemic.
Another limitation is that we evaluate genres/fandoms through individual tags, which means we are unable to wrangle multiple tags with similar meanings together. For example, ‘Fluff’ and ‘fluff’ mean the same thing, but since they are written differently, they are seen as separate generic tags in our data. In the future, we may re-scrape the data to consider tags with different writing but the same meaning as a single tag to improve the accuracy of our findings.
Bibliography
NetworkX. (n.d.). Greedy modularity communities. NetworkX Documentation. https://networkx.org/ documentation/stable/reference/algorithms/generated/ networkx.algorithms.community.modularity_max.greedy_modularity_communities.html
NetworkX. (n.d.). NetworkX tutorial. NetworkX Documentation. https://networkx.org/documentation/ stable/tutorial.html
R/datasets. (2020, August 5). ArchiveOfOurOwn dataset. Reddit. https://www.reddit.com/r/datasets/ comments/i254cw/archiveofourown_dataset/?rdt=61540
Media Attributions
- Screenshot
