John and Marcia Price College of Engineering
21 ClaraVisio: Computational DeFogging via Image-to-Image Translation on a Novel Free-Floating Fog Dataset
Amir Zarandi and Rajesh Menon
Faculty Mentor: Rajesh Menon (Electrical and Computer Engineering, University of Utah)
ABSTRACT
ClaraVisio presents an innovative Image-to-Image (I2I) translation framework designed to transform foggy images into clear ones, addressing a critical challenge in autonomous vehicle technology. Building upon existing models like StereoFog and FogEye, ClaraVisio introduces a unique dataset of free-floating fog, collected using a custom-built setup. This setup, employing a Raspberry Pi and a 3D-printed cone, enhances free-floating fog conditions during image capture. The Pix2Pix model, trained on over a thousand pairs of foggy and clear images, achieved an average multi-scale structural similarity index measure (MS-SSIM) exceeding 90%. This approach, incorporating natural fog variations, contrasts with previous research using controlled fog environments. Despite the relatively small dataset, ClaraVisio demonstrates the effectiveness of this method for enhancing visibility in foggy images and lays the groundwork for further data collection and model refinement.
Introduction
Fog-induced low visibility poses a significant challenge to road safety and the advancement of autonomous driving technology. The Federal Highway Administration reports that fog accounts for over 38,700 vehicle crashes annually on US roads, resulting in approximately 600 fatalities [1]. As the automotive industry progresses towards higher levels of automation, the ability to navigate safely in adverse weather conditions becomes increasingly critical.
The Society of Automotive Engineers (SAE) defines Level 4 autonomy as the first stage where driver engagement is not required during system operation [2]. Conservative estimates project that Level 4 and 5 autonomous vehicles will constitute 8% of US vehicle sales by 2035. However, the struggle of both human drivers and current autonomous systems to operate effectively in fog and other adverse weather conditions remains a major barrier to achieving widespread Level 4 autonomy [3][4].
Computational defogging through Machine Learning (ML) emerges as a promising solution to this challenge. Image-to-Image (I2I) translation offers a powerful approach for converting foggy images to clear ones. Optimal results in I2I translation require paired-image datasets, where each clear image corresponds precisely to a foggy counterpart. However, acquiring such datasets poses significant difficulties, especially when dealing with naturally occurring fog.
Previous work in this field, such as StereoFog by Anton Pollock [5], utilized datasets of paired fogged and clear images and employed the pix2pix I2I ML framework. Similarly, FogEye by Moody, Parke, and Welch [6] implemented High Dynamic Range (HDR) imaging techniques. However, both these studies relied on entrapped fog, which fails to fully capture the complexity of real-world fog behavior.
ClaraVisio, Latin for “clear vision,” distinguishes itself by focusing on free-floating fog, which more closely mimics natural phenomena. This approach addresses a critical gap in existing research and datasets. To overcome the challenge of obtaining paired images with real-world fog, we developed a custom device, allowing us to create a unique dataset of 1,144 image pairs featuring free-floating fog—the first of its kind, to the best of our knowledge.
Building on this novel dataset, we trained a pix2pix I2I model to perform the translation from foggy to clear images. Our methodology involved the optimum hyperparameters previously studied by Pollock [5]. We invite the research community to explore and build upon our work, with all data, supplementary materials, and source code freely available through our project’s online repository [7].
METHODS
Camera Setup
To collect the ClaraVisio dataset, we developed a specialized camera setup to capture paired clear and foggy images in real-world conditions. The core of our setup consists of a Raspberry Pi 5 Processor as the central control unit, a camera module compatible with Picamera2 for high-quality image capture, a shutter button connected to GPIO for user- controlled image capture, and status LEDs for visual feedback on system status. A power bank provides portable power supply, while a custom 3D-printed funnel surrounds the camera to temporarily shield the area from wind (Fig. 1), ensuring consistent fog conditions during image capture.
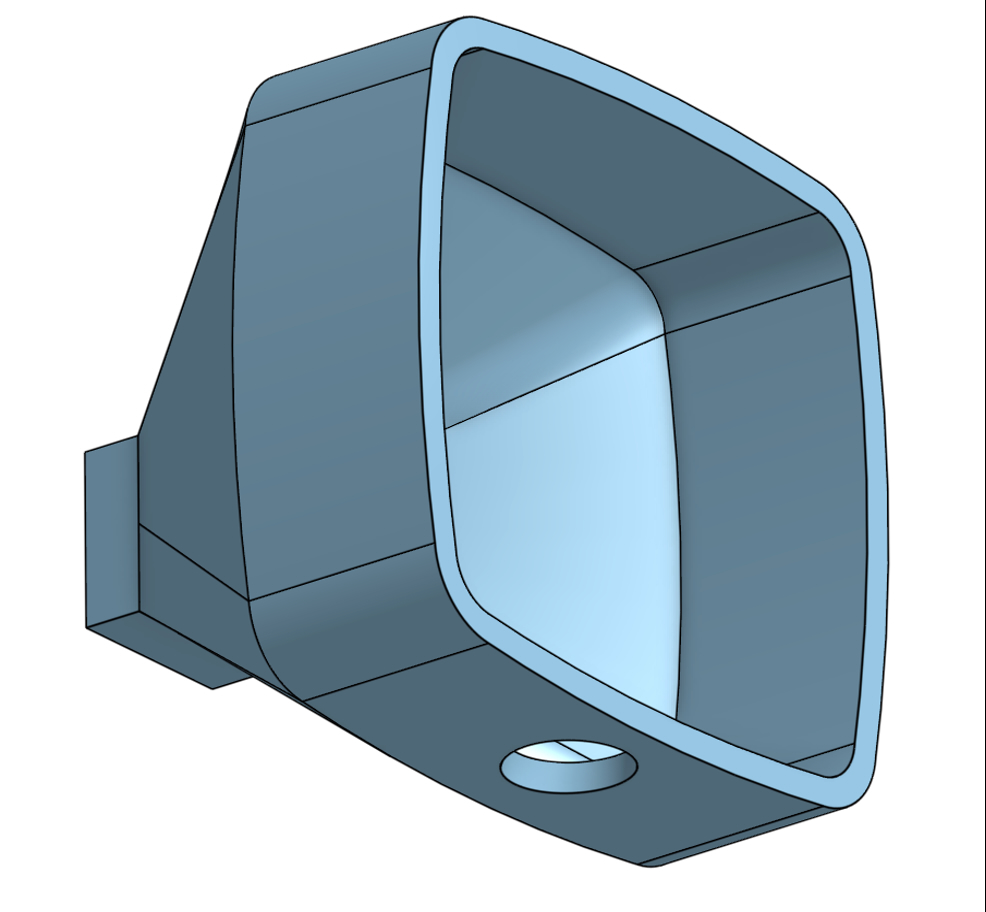
The entire setup was initially mounted on a cardboard box as a prototype, with plans for a custom-designed mount in future iterations. To ensure reproducibility, we have made available a comprehensive build guide, CAD model, and standard operating procedure (SOP) on GitHub [7].
The Raspberry Pi runs a custom Python script (main_pilot.py) that manages the image capture and upload process. Key software components include Python libraries such as gpiod, picamera2, and gpiozero for hardware control, as well as rclone configured for Google Drive synchronization. The script is set to run automatically on boot using crontab, ensuring immediate operation upon system startup.
The data collection process involves capturing an initial clear image, creating fog using a fog machine, capturing the foggy image, and automatically sorting the images into separate folders. A continuous syncing process with Google Drive ensures data backup and accessibility. Real-time status updates are provided through LED indicators, and a log file is maintained for troubleshooting and system monitoring.
Dataset
We collected a total of 1,144 image pairs in July 2024 on the University of Utah campus in Salt Lake City. The dataset nomenclature follows the collection date (ISO 8601 format) and run index for each day. Each run contains subfolders A and B, corresponding to clear and foggy images, respectively.
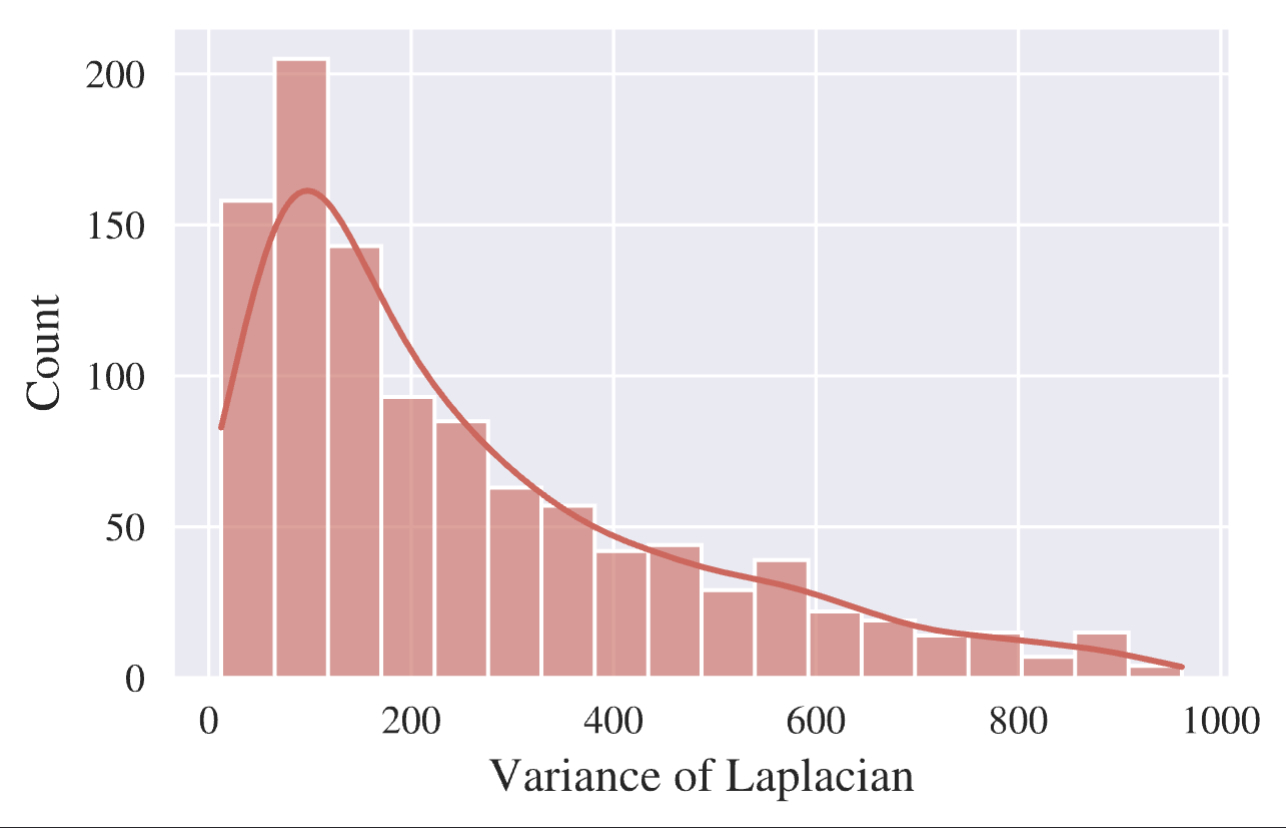
To quantify fogginess, we used the variance of the Laplacian [8], [9] (labeled as vL), as image blurring is a common effect of fog (Fig. 2). The distribution of Laplacian values within our dataset (with outliers removed using the interquartile rule) peaks around 100, retaining 92.13% of the data points.

Pix2Pix Model
We employed a pix2pix conditional Generative Adversarial Network (cGAN) model with average gradient sorting for I2I translation [10]. The model was specifically trained to transform foggy images into clear ones. Unlike traditional GANs, cGANs extend the framework by conditioning both the generator (G) and discriminator (D) on additional information (y) [11], [12].
Our implementation utilizes a paired (supervised) dataset, where each foggy image corresponds to a clear counterpart. We also incorporated a reverse constraint, requiring that the reverse image (translated from clear to foggy) maintains optimal similarity to the original foggy image. This bidirectional approach enhances the model’s ability to preserve important image features during the translation process [13].
Training
For the final model training, we augmented the dataset using the Augmentor Python library [14]. Augmentation techniques included left-right flip and random zoom with a 30% probability, applied only to the training subset to prevent data leakage.
The dataset was preprocessed to be consistent with pix2pix requirements. We used optimized hyperparameters from [5], including normalization, loss function, netD type, number of layers in the discriminator, netG type, GAN mode, number of generative filters in the last convolutional layer, number of discriminative filters in the first convolutional layer, and network initialization type. The best-performing model was trained for 35 epochs plus 25 decay epochs.
Metrics
To evaluate model performance, we employed both visual inspection and objective metrics. The metrics used include Mean Square Error (MSE), Peak Signal-to-Noise Ratio (PSNR), PEARSON correlation coefficient [15], Normalized Cross Correlation Coefficient (NCC) [16], Structural Similarity Index (SSIM) [17], Complex Wavelet-SSIM (CW-SSIM) [18], and Multi- scale SSIM (MS-SSIM) [19]. We implemented MS-SSIM as the optimum loss function for our model training.
RESULTS
Dataset Analysis:
To compare our ClaraVisio dataset with the StereoFog dataset, we standardized image resolutions and analyzed various measures. In terms of non-homogeneity (blur_std / blur_mean), ClaraVisio scored 0.877 compared to StereoFog’s 0.493, exhibiting more varied blur patterns across images. The sharpness measure (edge_density * blur_kurtosis) showed ClaraVisio at 0.074 and StereoFog at 0.036, indicating a greater presence of both clear and blurred regions within the same images for ClaraVisio.
Blur statistics revealed that ClaraVisio had a mean of 8.859 and standard deviation of 7.467, while StereoFog had a mean of 1.860 and standard deviation of 1.032. This demonstrates more overall blur and variation in blur across images in the ClaraVisio dataset. Edge density analysis showed ClaraVisio at 0.0223 and StereoFog at 0.00217, indicating that ClaraVisio preserves more structural information despite the fog, with an order of magnitude higher edge density.
2) Model Performance:

Our best-performing model achieved impressive results on the ClaraVisio dataset (Fig. 3). The average metrics included a Pearson correlation of 0.36, Mean Square Error (MSE) of 0.007, Normalized Cross Correlation (NCC) of 0.95, Structural Similarity Index (SSIM) of 0.78, Complex Wavelet-SSIM (CW-SSIM) of 0.86, and Multi-scale SSIM (MS-SSIM) of 0.91. The model produces plausible reconstructions even for images with dense fog, with better results for lighter fog conditions.
We investigated the effect of fog density on the performance of our computational defogger using the variance of the Laplacian (vL) as a measure of fog density. The CW-SSIM score clearly drops as the fog density increases (vL decreases) for all datasets, with the ClaraVisio dataset exhibiting higher fog densities and consequently worse performance.
CONCLUSION
ClaraVisio introduces a novel approach to computational defogging, leveraging a unique dataset of free-floating fog and an optimized pix2pix model. Our achievements include the creation of a distinctive dataset capturing real-world fog conditions, development of a custom data collection setup ensuring consistent fog capture, and training of a high-performing I2I translation model for fog removal. The potential applications of this work extend to autonomous vehicles, traffic safety systems, and computer vision tasks in adverse weather conditions.
Future work directions include expanding the dataset with diverse locations beyond the university campus, exploring alternative I2I architectures, testing the model on real-world fog scenarios, developing methods to gauge potential model failures, and improving defogging robustness for object detection and text recognition. By addressing the challenges of fog- induced low visibility, ClaraVisio contributes to the advancement of autonomous driving technology and road safety in adverse weather conditions.
Footnotes
- Federal Highway Administration, “Low Visibility – FHWA Road Weather Management,” Feb. 2023. [Online]. Available: https://ops.fhwa.dot.gov/weather/weather_events/low_visibility.htm
- National Highway Traffic Safety Administration, “Automated Vehicles for Safety — NHTSA.” [Online]. Available: https://www.nhtsa.gov/technology-innovation/automated-vehicles-safety
- Y. Zhang, A. Carballo, H. Yang, and K. Takeda, “Perception and Sensing for Autonomous Vehicles Under Adverse Weather Conditions: A Survey,” ISPRS Journal of Photogrammetry and Remote Sensing, vol. 196, pp. 146–177, Feb. 2023. [Online]. Available: http://arxiv.org/abs/2112.08936
- S. Zang, M. Ding, D. Smith, P. Tyler, T. Rakotoarivelo, and M. A. Kaafar, “The Impact of Adverse Weather Conditions on Autonomous Vehicles: How Rain, Snow, Fog, and Hail Affect the Performance of a Self-Driving Car,” IEEE Vehicular Technology Magazine, vol. 14, no. 2, pp. 103–111, Jun. 2019.
- A. Pollock, “StereoFog,” GitHub repository, 2022. [Online]. Available: https://github.com/apoll2000/stereofog
- D. Moody et al., “FogEye,” GitHub repository, 2023. [Online]. Available: https://github.com/Chan-man00/fogeye
- A. Zarandi, “ClaraVisio,” GitHub repository, 2024. [Online]. Available: https://github.com/amirzarandi/claravisio
- R. Bansal, G. Raj, and T. Choudhury, “Blur image detection using Laplacian operator and Open-CV,” in 2016 International Conference System Modeling & Advancement in Research Trends (SMART), Nov. 2016, pp. 63–67.
- Kinght, “Answer to ‘What’s the theory behind computing variance of an image?’,” Jan. 2018. [Online]. Available: https://stackoverflow.com/a/48321095
- P. Isola, J. Y. Zhu, T. Zhou, and A. A. Efros, “Image-to-image translation with conditional adversarial networks,” in Proceedings of the IEEE conference on computer vision and pattern recognition, 2017, pp. 1125-1134.
- M. Mirza and S. Osindero, “Conditional generative adversarial nets,” arXiv preprint arXiv:1411.1784, 2014.
- I. Goodfellow et al., “Generative adversarial nets,” in Advances in neural information processing systems, 2014, pp. 2672-2680.
- Z. Yi, H. Zhang, P. Tan, and M. Gong, “DualGAN: Unsupervised dual learning for image- to-image translation,” in Proceedings of the IEEE international conference on computer vision, 2017, pp. 2849-2857.
- M. D. Bloice, “Augmentor — Augmentor 0.2.12 documentation,” 2023. [Online]. Available: https://augmentor.readthedocs.io/en/stable/
- Chicago Booth Center for Decision Research, “Pearson Correlation Pixel Analysis.” [Online]. Available: https://mbrow20.github.io/mvbrow20.github.io/PearsonCorrelationPixelAnalysis.html
- A. Winkelmann, “The Normalized Cross Correlation Coefficient,” 2018. [Online]. Available: https://xcdskd.readthedocs.io/en/latest/cross_correlation/cross_correlation_coefficient.html
- Z. Wang, A. Bovik, H. Sheikh, and E. Simoncelli, “Image quality assessment: From error visibility to structural similarity,” IEEE Transactions on Image Processing, vol. 13, no. 4, pp. 600–612, Apr. 2004.
- Z. Wang and E. Simoncelli, “Translation insensitive image similarity in complex wavelet domain,” in Proceedings. (ICASSP ’05). IEEE International Conference on Acoustics, Speech, and Signal Processing, 2005., vol. 2, Mar. 2005, pp. ii/573–ii/576 Vol. 2.
- Z. Wang, E. Simoncelli, and A. Bovik, “Multiscale structural similarity for image quality assessment,” in The Thrity-Seventh Asilomar Conference on Signals, Systems & Computers, 2003, vol. 2, Nov. 2003, pp. 1398–1402 Vol.2.
Media Attributions
- 137489262_picture1
- Screenshot
- Screenshot
- 146881378_picture3
