Transcription
Objective 6.3
6.3.1 State the essential features of transcription.
6.3.2 Characterize exons and introns.
6.3.3 Explain the process by which pre-mRNA is edited to messenger RNA.
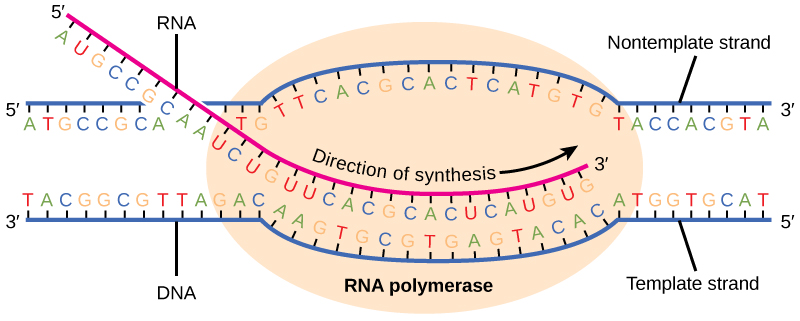
Transcription takes place in the nucleus, where DNA is packaged and stored. Reference books never leave the library. DNA never leaves the nucleus. The double-stranded DNA is transcribed to single-stranded RNA, with the A–T, C–G, G–C, and T–A base pairs of DNA coding for A, C, G and U bases along an RNA backbone. Remember that thymine in DNA is replaced by the very similar base uracil in RNA.
The enzyme used to make RNA from a DNA template is called RNA polymerase. This is a great name for this enzyme, because it makes a polymer out of RNA nucleotides (ribonucleotides).
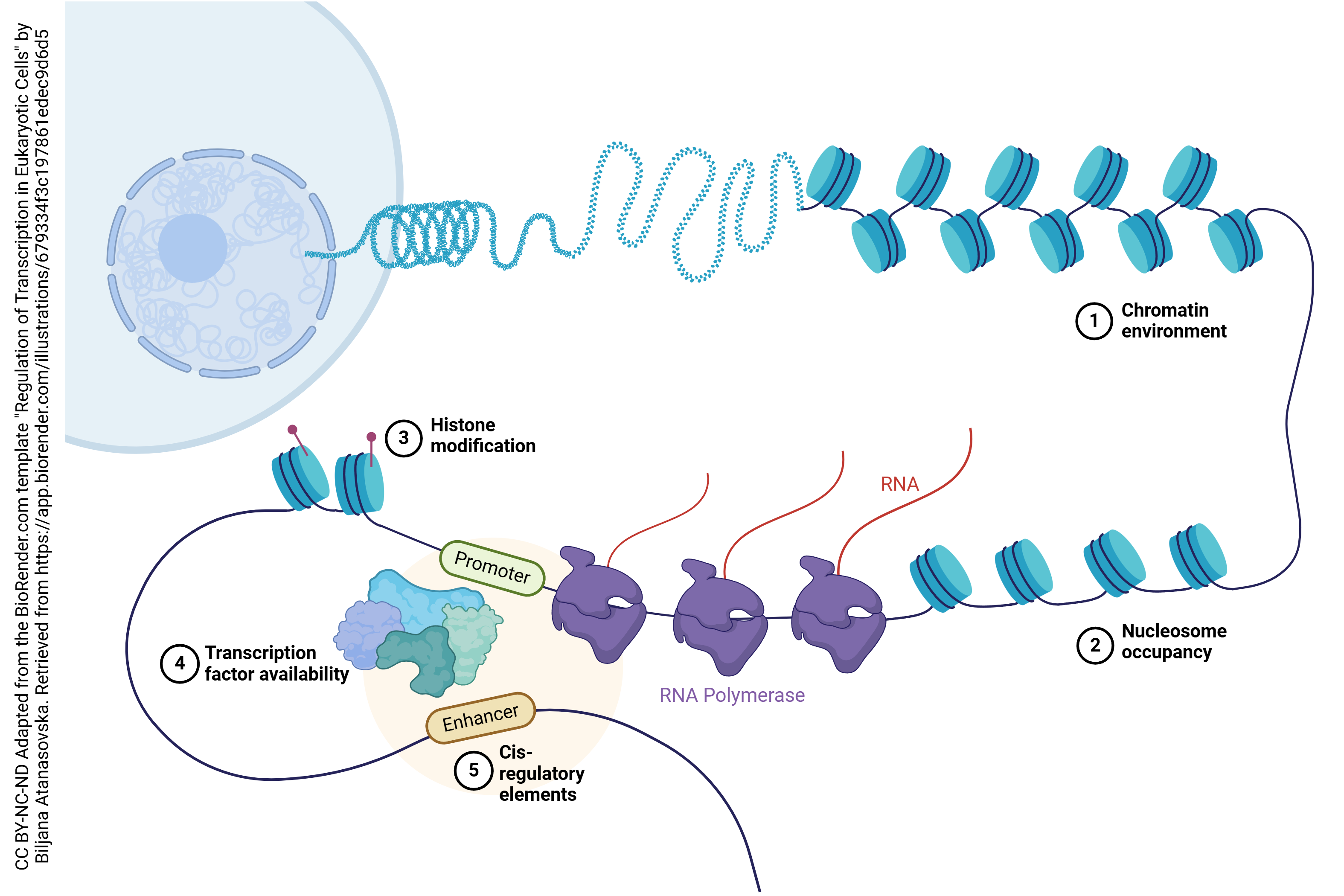
All cells have the same DNA, but not all cells have the same protein. How is this accomplished? It must be that some genes are switched “on” while others are switched “off”. For example, both your intestinal cells and your brain cells have the same DNA, but for intestinal cells we need to switch on enzymes and other proteins that are used to break down and move nutrients across the cell, while in brain cells we need to switch on enzymes and other proteins that are used to send signals from one cell to another.
This process of switching genes “on” or “off” is called transcriptional control: we control the process of transcription by making it more likely that RNA polymerase will bind to the gene we want to turn “on”, or less likely that RNA polymerase will bind to the gene we want to turn “off”.
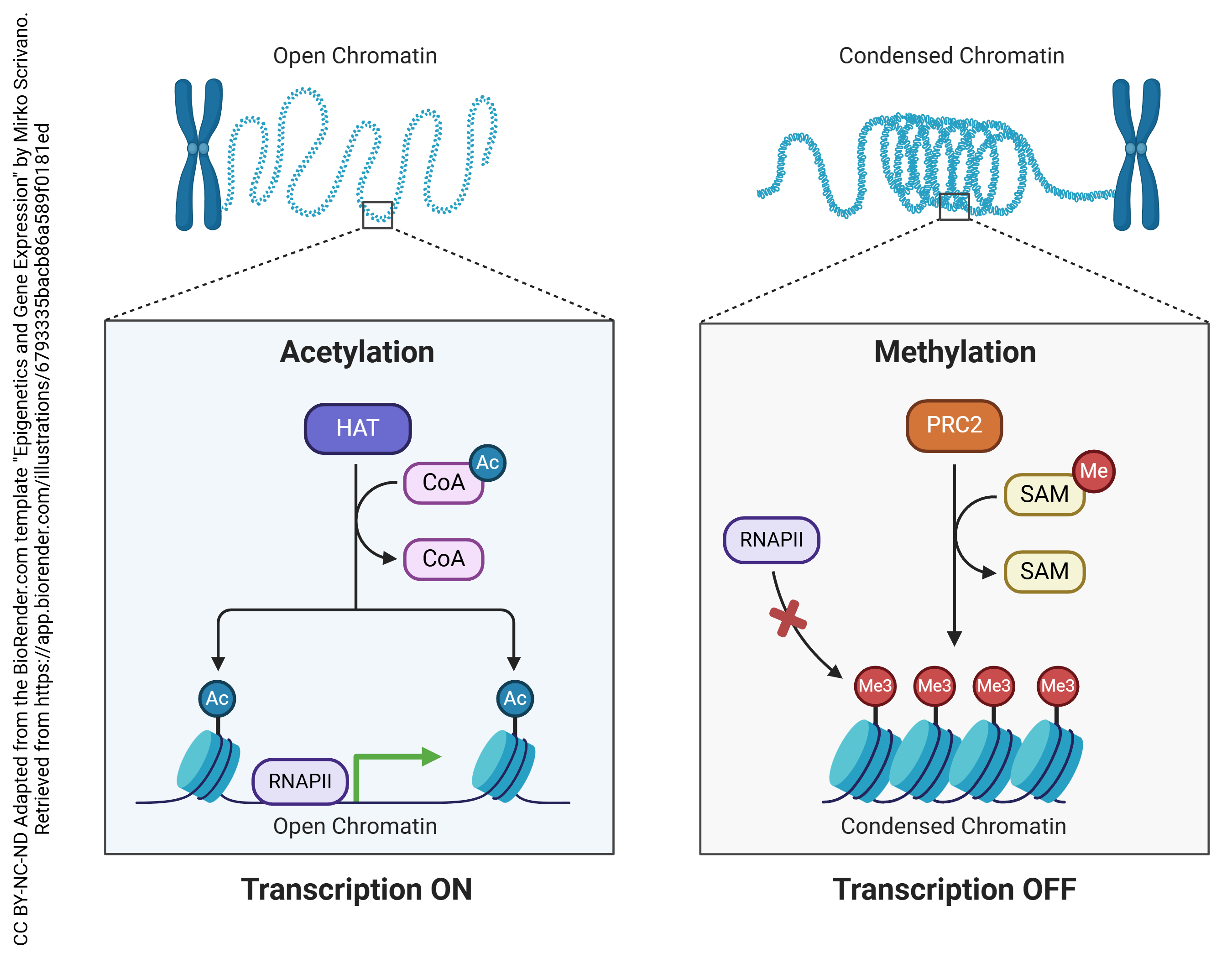
This can be done in a fairly brutish fashion by physically blocking RNA polymerase. When DNA is packed tightly, as it is in heterochromatin, the RNA polymerase cannot access the DNA template and the genes in this region are turned “off”.
If we add an acetyl (–CH3COOH) group to histones, the DNA is held more loosely and the genes in that region are turned “on” (top). If we add a methyl group (–CH3) group to histones, the DNA can pack tightly and the genes in that region are turned “off” (bottom).
We can achieve a finer level of control over transcription by adding or removing methyl (–CH3) groups from the DNA in the gene itself, rather than the histone it wraps around. If we remove methyl groups (left), the gene is turned “on”. If we add methyl groups, they block RNA polymerase binding and the gene is turned “off”. Notice that this is a more-or-less permanent change in the structure of DNA, so these mechanisms are used when we want to permanently shut down a gene or a block of genes.
Also note that life events (stressful events, diseases, bad habits) can permanently alter the DNA and make it more or less likely that key genes will be transcribed. This can even happen in fetal life: mothers subjected to stressors while pregnant are more likely to give birth to individuals with autism, for example. Alterations in the fetal environment cause a permanent change in that child’s DNA. It is important to note that this is not in any way the mother’s fault: most, if not all, of these stressors are outside of the mother’s control.
These permanent alterations in DNA are called epigenetic modifications. Epi– means “over and above” and –genetics of course means what is coded in DNA. Epigenetics are over and above the Central Dogma of Molecular Biology.
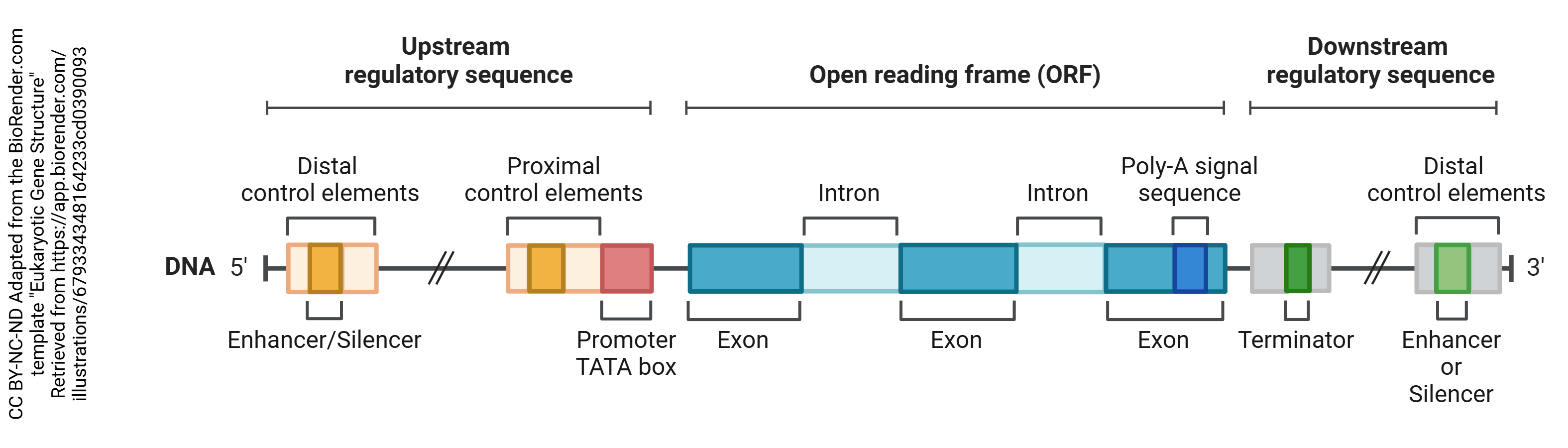
Another way to change the expression of proteins is to temporarily and dynamically change the transcription of certain genes. “Upstream” or on the 5’ side of the gene itself, there are regulatory sequences in the DNA that provide the cell with “on” or “off” switches.
The most important of these, that do exactly what you expect them to do from their name, are called promoters: they promote the transcription of a gene.
The “upstream” area of DNA that is not translated (i.e. not made into protein) is called the 5’ untranslated region (5’-UTR).
There is a place that stops RNA polymerase called the terminator (named before the movie character). This is in the 3’-UTR. There are also regulatory regions in the “downstream” area of the gene.
Also shown in the diagram above are the regions that are “edited out” of a gene; we will discuss these a bit later.
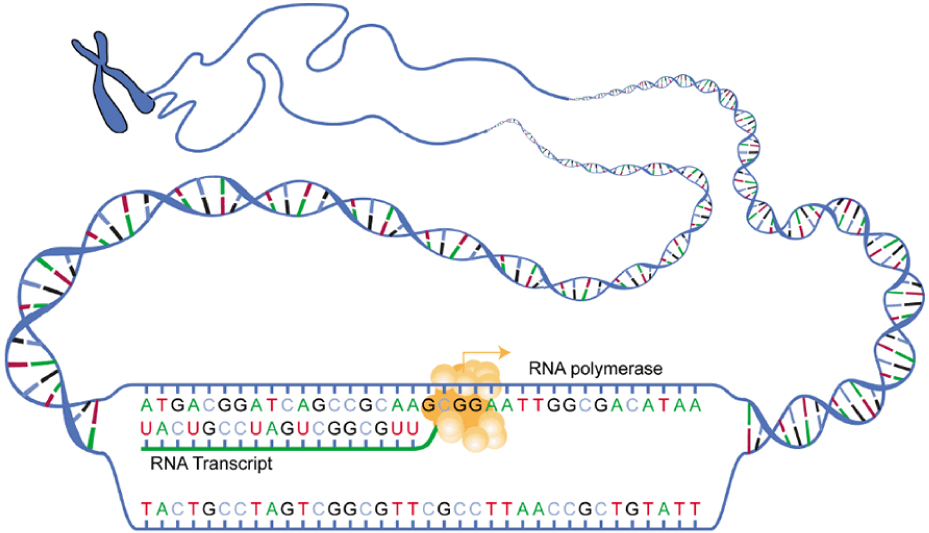
Most diagrams show the structure of a gene as a long line. In reality, when RNA polymerase is coaxed into transcribing a gene, the transcription factors that bind to the promoter region form a loop of DNA, as shown here. The phrase “transcription factors” describes a wide variety of nucleic acids and proteins that can bind to DNA and alter gene expression. We saw a few of these in Unit 3 when we talked about the shape of proteins that can interact with DNA.
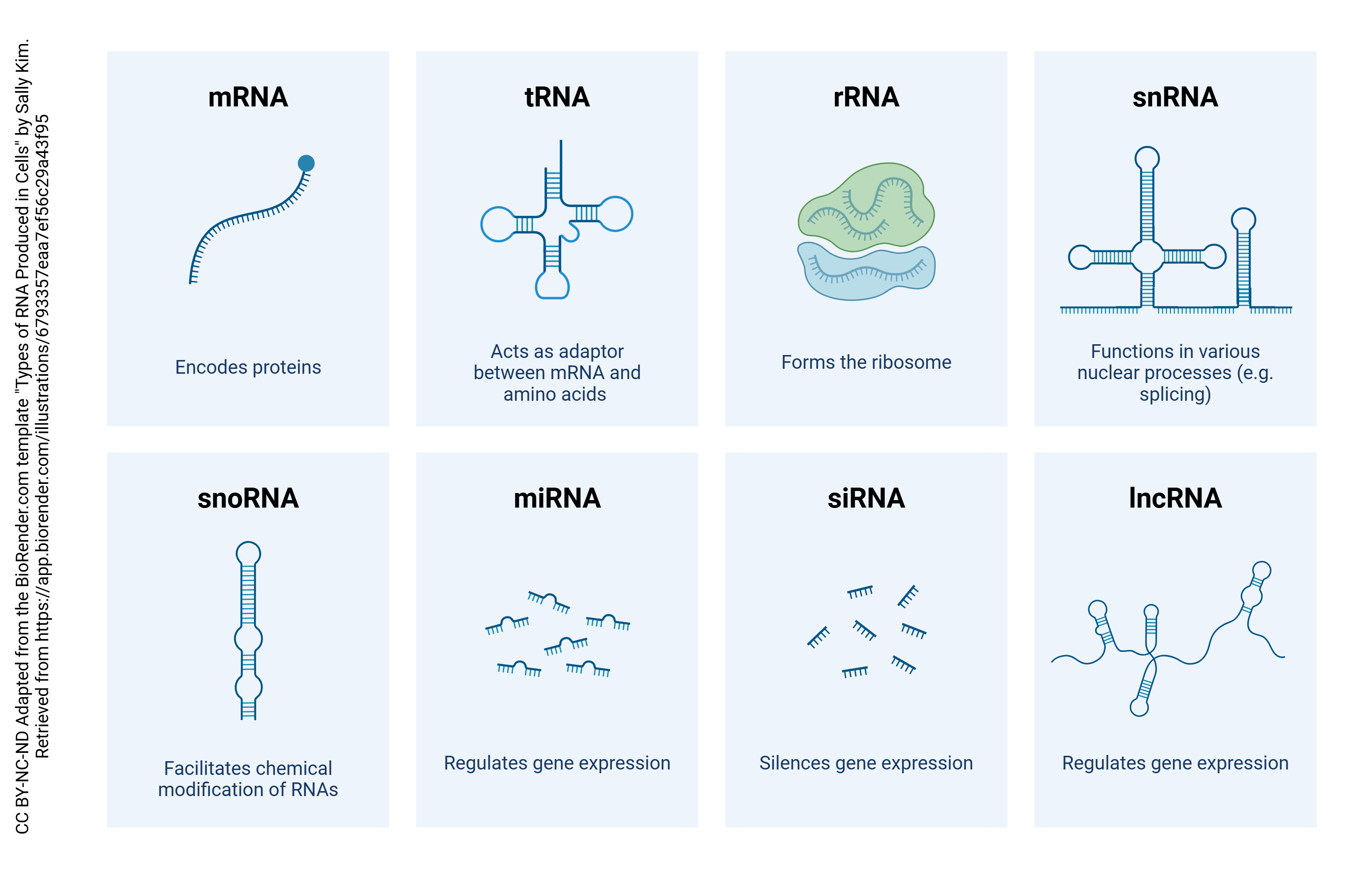
Finally, while many people would define a gene as a segment of DNA that codes for a protein, it’s important to remember that not all genes do that. Some code directly for the RNA molecules that are important in the process of translation (next objective). The RNA that codes for a protein is called messenger RNA (mRNA) because it carries a message to the apparatus that makes protein. If it doesn’t code for a protein, it’s called non-coding RNA (ncRNA) and there are two of these we’ll talk about (ribosomal RNA and transfer RNA) and a whole bunch we won’t talk about that have enzymatic activity even though they’re not proteins (ribozymes).
The RNA made by RNA polymerase and destined to code for protein is called pre-mRNA or the primary transcript. The primary transcript has to be edited to its final form before it is shipped out of the nucleus. The final edited form, which is shipped out of the nucleus, is what is formally called mRNA.
The exon is the portion of the DNA that is expressed, or made into protein.
The intron is the portion of the DNA that is not made into protein and must be edited out.
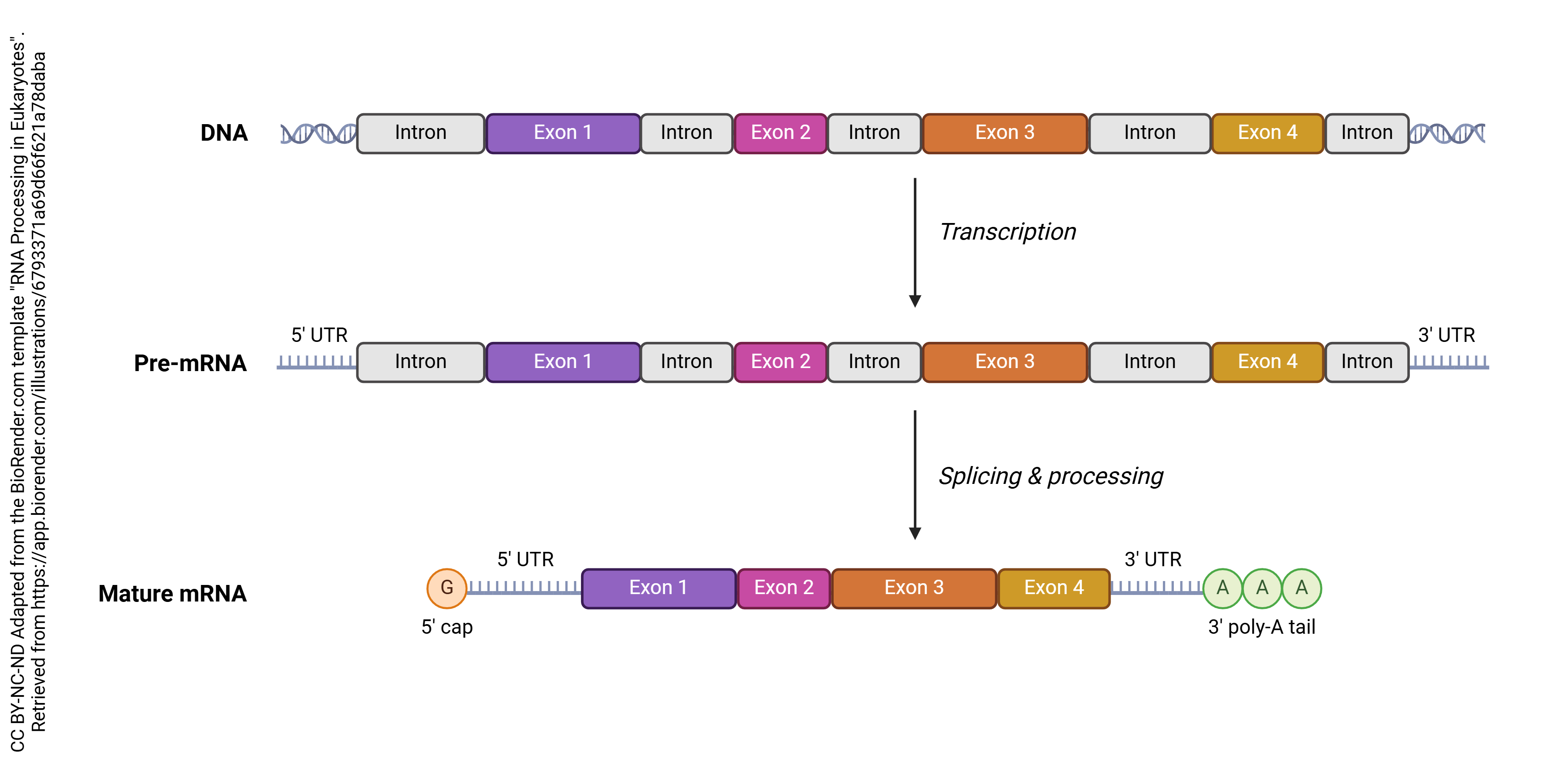
The process of transcribing from a segment of DNA (a gene) is shown here). The introns or intervening regions are edited out (grey regions). Exons are spliced together to make the final mRNA. This mRNA will be read on a ribosome and translated to a protein. We will study the process of translation in the following objective.
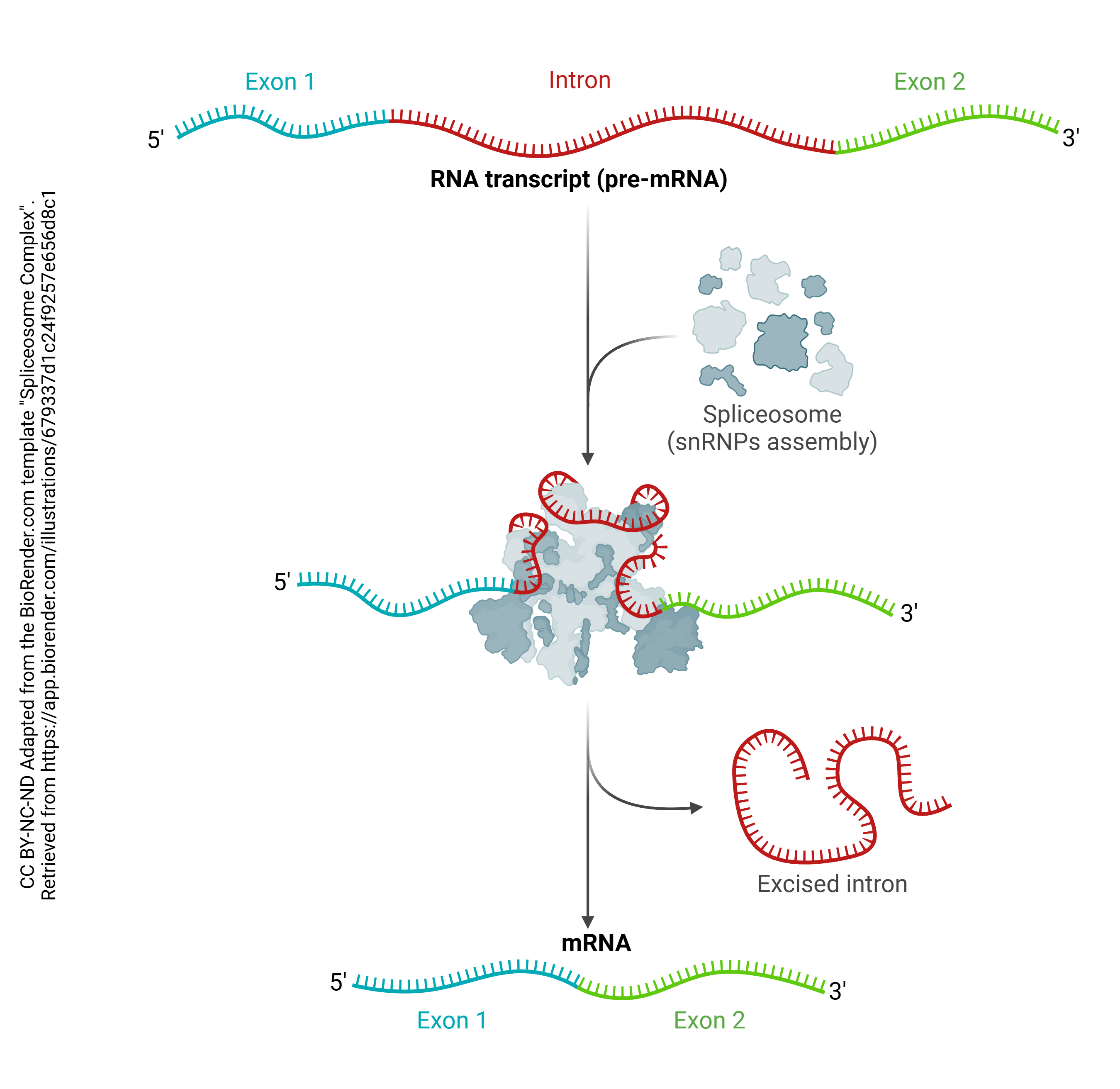
In order to create mRNA, the introns must be sliced out and the exons stitched together. This is accomplished by an organelle called the spliceosome, which is made up of several small nuclear ribonucleoprotein particles, or snRNPs (“snurps”). A structure called a lariat is formed, the intron is cut out, and the ends of the exon are stitched together.
This snRNP participates in the editing process that cuts and splices pre-mRNA into mRNA.
The edited transcript (now officially called mRNA) passes through a pore in the nuclear envelope. Once in the cytoplasm, it is used as the blueprint for protein synthesis at the ribosome protein factory.
An “average” chromosome has 150 million base pairs. Every so often, a string of base pairs about 100,000 nucleotides long will form a gene. There are about 1,000 genes on a chromosome, so that means only about 0.7% of the chromosome is used for genes.
Clinical Connection
Mutations, as you might expect, can mess up the process of splicing. This has been shown for the blood disorder called β-thalassemia. β-globin is a protein that makes up half of hemoglobin, the oxygen carrying protein of red blood cells. An abnormal splicing site in β-globin is created by mutation, a change in the sequence of DNA bases. Any mutations in the spliced region of genes, even though they may lie in introns and are not directly made into proteins, may alter the normal stability of mRNA and therefore the translation of β-globin mRNA into β-globin protein, and the blood is unable to carry normal amounts of oxygen (a symptom called anemia).
Media Attributions
- U06-020 transcription © Clark, Mary Ann; Douglas, Matthew; Choi, Jung is licensed under a CC BY (Attribution) license
- U06-021 transcription © National Human Genome Research Institute is licensed under a Public Domain license
- U06-022 Epigenetics and Gene Expression © Mirco Scrivano adapted by Elizabeth Rebarchik is licensed under a CC BY-NC-ND (Attribution NonCommercial NoDerivatives) license
- U06-023 Eukaryotic Gene Structure © BioRender adapted by Elizabeth Rebarchik is licensed under a CC BY-NC-ND (Attribution NonCommercial NoDerivatives) license
- U06-024 Regulation of Transcription in Eukaryotic Cells © Atanasovska, Biljana adapted by Elizabeth Rebarchik is licensed under a CC BY-NC-ND (Attribution NonCommercial NoDerivatives) license
- U06-025 Types of RNA Produced in Cells © Kim, Sally is licensed under a CC BY-NC-ND (Attribution NonCommercial NoDerivatives) license
- U06-027 RNA Processing in Eukaryotes © BioRender is licensed under a CC BY-NC-ND (Attribution NonCommercial NoDerivatives) license
- U06-028 Spliceosome Complex © Elizabeth Rebarchik is licensed under a CC BY-NC-ND (Attribution NonCommercial NoDerivatives) license

{kind=link}