Features of Organic Molecules
Objective 3.1
3.1.1 Define organic molecules.
3.1.2 Name the features of an organic molecule.
3.1.3 List the essential features of the four main categories of organic molecules: proteins, lipids, carbohydrates, and nucleic acids.
Organic molecules are those that contain carbon. This is important, because carbon is so versatile. It always makes four bonds. Note its position in the periodic table: it can give away four electrons or gain four electrons to complete its shell.

Those four bonds can be single, double or triple covalent bonds. Single and double bonds are commonly found in organic molecules from living things; triple bonds are uncommon in nature.
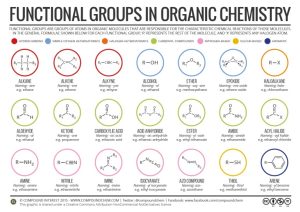
In Unit 2 (Chemistry), we learned about functional groups, common combinations of elements found in many biological molecules. We will need to know these more than ever as we work through this Unit (Biochemistry). We are developing a common language so students understand what we mean when we refer to the following functional groups, most of which you should have learned in Unit 2:
- alcohol
- ether
- aldehyde
- ketone
- carboxylic acid (carboxyl)
- ester
- amine (amino)
One of the most important categories of biological molecules, alcohols, have no section their own so we will consider them now.
Names of alcohols, just like the word “alcohol”, end in –ol.
The first alcohol we need to know is usually called just “alcohol”, but is also called “grain alcohol” from its distillation method or “ethanol” (abbreviated EtOH on patient charts) from its chemical name.
| ethanol | 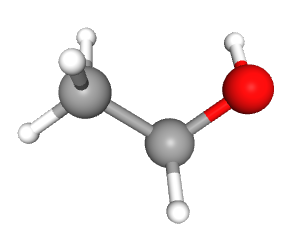 |
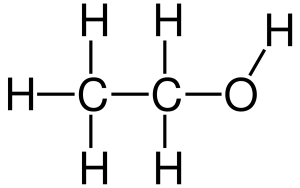 |
The second alcohol we need to know has three hydroxyl (–OH) groups, one for each carbon. In the medicine cabinet and in the industrial kitchen, it’s called glycerin, but in the chemistry lab and in biochemistry it’s called glycerol.
| glycerol | 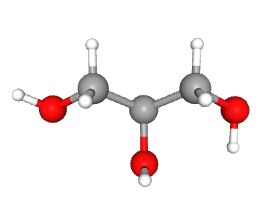 |
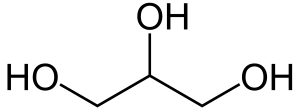 |
Now let’s revisit the functional groups we were introduced to (but not tested on) in Unit 2. Now these are fair game for the unit quiz and exam.

These organic functional groups can be combined in various ways to make interesting compounds. For example, it has been known since antiquity that willow bark has a pain-relieving substance in it; our ancestors chewed on willow bark to relieve pain. This was less than ideal, not just because of the squirrel and bird poop they were chewing on, but because willow bark is not pure. In the late 19th century, German chemists isolated the active ingredient in willow bark: salicylic acid.
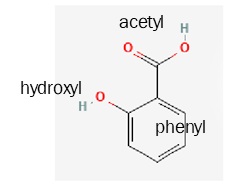
Salicylic acid is made up of a phenyl ring, a hydroxyl group, and an acetyl group. (When a carboxylic acid group is attached to a second carbon, it is called acetyl. This is confusing but not only are we stuck with it, but it will be an important part of Unit 5. Acetic acid, or vinegar, is a methyl group plus a carboxyl group.)
But when the chemists tried to give salicylic acid to people, it worked to relieve pain but also caused mouth lesions and stomach irritation, which was really no help at all. So being chemists, they started modifying the salicylic acid to see if they could make it work without causing damage.
If they added a methyl (–CH3) group in place of the hydrogen on the acetate group, they got methyl salicylate (wintergreen oil). This is pleasant to smell and has some pain relieving effects, but they were chemists, so they kept playing around.
Next they added a carboxyl group via an ester linkage where the hydroxyl used to be. This compound is called acetyl salicylic acid or ASA for short. The chemists that did this work were employed by Bayer GmbH, a German company.
Then World War I came and the Americans were extremely mad at the Germans. One of the things they did was to take away Bayer’s copyright on the name “Aspirin” and make it public domain. Everywhere else in the world, “Aspirin” is still copyrighted by Bayer and so the generic form of Aspirin is called “ASA”. The bottle pictured above is from Canada, for example. In the US, acetyl salicylic acid is called “aspirin”.
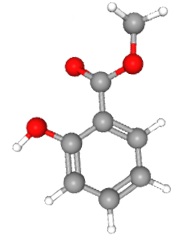
| salicylic acid
(active compound in the folk medicine willow bark) |
 |
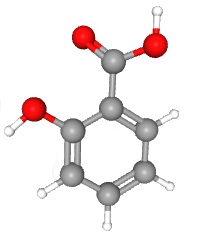 |
| methyl salicylate
(wintergreen oil) |
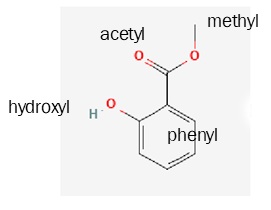 |
 |
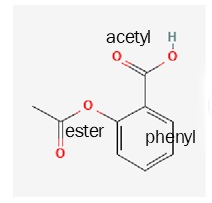
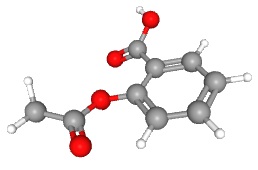
| acetyl salicylic acid
(aspirin) |
 |
 |
Another example is the formation of fats. We’ll look at fats in detail in Objective 5, so don’t stress too much about the details here. It’s just a larger version of the story about dehydration synthesis we started telling you in Unit 2.
Each of the three hydroxyl groups in glycerol can be chemically modified. Taking off the –H from a carboxyl group at the end of fatty acids and the –OH from glycerol makes HOH or water. Remember that an acid is a hydrogen donor so the hydrogen in the carboxyl group of fatty acids is ready to leave anyway. That makes an ester linkage each place a string of hydrocarbons (fats) is added.
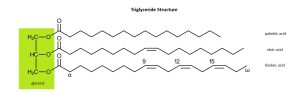
If we extract fats from palm seeds, we get palmitic acid, a fatty acid.
If we extract fats from olives, we get oleic acid, a fatty acid.
If we extract fats from flax then we get linoleic acid, a fatty acid (Latin linum–, “flax” + –oleum, “oil”). (Note that linoleum, originally canvas soaked in flaxseed oil, and linen, a cloth made from flax, come from the same Latin roots.)
The double bonds in oleic acid and linoleic acid cause the carbon chains in these molecules to fold back on themselves, which will be important in Objective 5 when we discuss saturated vs unsaturated fatty acids.
The ester linkages which hold the fatty acids onto the glycerol backbone were formed by dehydration synthesis: removing water to make a larger molecule. We introduced dehydration synthesis in Unit 2.
The straight arrow is the main chemical reaction. The curved arrow indicates a by-product of the chemical reaction, in this case water.
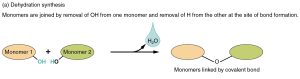
The –OH groups are ripe for a dehydration synthesis reaction (we learned this in Unit 2 and will look at it again in the objectives related to Amino Acids, Proteins, and Polysaccharides). Remember that in the dehydration synthesis reaction, a new covalent bond is formed, joining two smaller molecules into a larger one (synthesis). In the process, a –H is removed from one of the smaller molecules and a –OH from the other; these HOH are combined into water (H2O).
An important part of Objective 3 is classifying amino acid –R groups as (polar) acidic, (polar) basic, polar uncharged, or non-polar. How do we know how to make this classification? It’s all down to hydrogen bonding, and how electrons are distributed unequally or equally in a molecular structure.
Polar charged and polar uncharged (hydrophilic) groups
When an electronegative element like oxygen or nitrogen bonds to hydrogen, hydrogen’s single electron is pulled away from the hydrogen nucleus and tends to spend more time closer to the oxygen nucleus or the nitrogen nucleus. Recall that we called this type of bond polar covalent because the electron is pulled towards the electronegative element’s nucleus, forming a dipole. One end of the molecule has a small net negative charge and one end has a small net positive charge.
If the negatively charged electrons are pulled hard enough, and the net positive charge becomes high enough as a result, the hydrogen ion (H+) just books it and leaves, leaving its electron behind with the oxygen (O–). This happens, for example, in a carboxyl group, which is why –COOH is called a carboxylic acid: it tends to donate its hydrogen ion, forming –COO– plus H+.
Amino groups (–NH2) tend to act as hydrogen ion acceptors (bases), taking on an extra hydrogen ion (also called a proton, H+) and forming a positively charged amino group (–NH3+).
If the hydrogen is available for hydrogen bonding, but the electron is not pulled hard enough to completely donate the proton (H+), we call this an uncharged polar structure because there are an equal number of protons and electrons and therefore no net charge. This kind of structure can still form hydrogen bonds with water, however.
Because all of the above structures easily mix with water by forming hydrogen bonds, they are called hydrophilic (“water loving”).
Non-polar (hydrophobic) groups
When a compound shares electrons equally, there are no electrons or protons available for hydrogen bonding.
One common circumstance where this happens is a resonance structure. Chemists use the term resonance to describe where electrons are shared through a large part of the molecule’s structure. The purest example of this is in the compound benzene (C6H6), also called a phenyl ring when it is available to form a bond with another atom (–C6H5).
 The idea of resonance was first proposed by the 19th century German chemist August Kekulé. According to legend, while trying to envision the structure of benzene (C6H6), he had a daydream of an ouroboros, a snake swallowing its own tail.
The idea of resonance was first proposed by the 19th century German chemist August Kekulé. According to legend, while trying to envision the structure of benzene (C6H6), he had a daydream of an ouroboros, a snake swallowing its own tail.
This daydream image gave him an idea: what if, like the parts of an ouroboros, a benzene or phenyl ring has no beginning and no end? What if electrons are equally shared throughout the structure?
In a resonance structure, there is an equal probability of finding any given electron anywhere in the structure.
Compare this to a dipole like water, where there is a slightly greater probability of finding an electron near the oxygen nucleus than there is near the hydrogen nucleus. Remember that we called this a dipole, and labeled the resulting partial positive charge at the hydrogen end of the water molecule with δ+ and the partial negative charge at the oxygen end of the water molecule with a δ–. Dipoles, formed from polar covalent bonds, like water. The resulting molecules are called polar or hydrophilic (“water-loving”).
Molecules with resonance structures, and any other molecule where there is equal sharing of electrons, cannot form hydrogen bonds with water and so are called non-polar or hydrophobic (“water-hating”).
The functional groups and chemical compounds we have mentioned in this introduction form the building blocks of life.
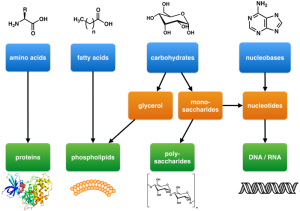
There are four main kinds of biological molecules.
Amino acid monomers are joined together into a protein polymer.
Three fatty acid monomers are joined to glycerol to form triglycerides, or two fatty acid monomers are joined to a complex chemical grouping with oxygen, nitrogen, and phosphorus to form phospholipids. These are collectively called lipids or fats.
A sugar (carbohydrate) monomer (monosaccharide) can be joined to a nitrogenous base to form DNA or RNA monomers, or sugars can be joined together into pairs (disaccharide) or large chains (cellulose, starch, or glycogen).
The four classes of biological molecules we’ll consider, then, are:
- proteins
- lipids (fats)
- carbohydrates (sugars)
- nucleic acids
These polymers can be quite large. For example, one kind of starch, amylopectin, a polymer made up of about 500,000 glucose monomers (162 Daltons each), may have a molecular weight as high as 72 million Daltons. Proteins in connective tissues, polymers of about 10,000 amino acids (about 100 Daltons per amino acid) can have molecular weights close to 1 million Daltons. The human chromosome 1 is a single DNA polymer with about 250 million nucleotides (about 330 Daltons each), giving it a molecular weight of about 80 billion Daltons. Remember that 1 Dalton = 1 atomic mass unit.
The first three of these four categories of organic compounds — proteins, lipids (fats), and carbohydrates — are components of all foods, and make up the three categories familiar from US government-mandated nutritional labels (“Nutrition Facts”). (Nucleic acids are not an important part of most foods.)

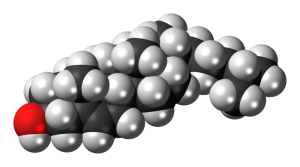
A Note on Space-Filling Models of Molecules & Chemical Shorthand
In this course, we’ll rely heavily on space filling models of molecules and on shorthand notation of organic molecules.
The space filling models were introduced in Unit 2. Formally, they show what are called van der Waals radii of atoms. Even more formally, this is the zone where the probability of finding an electron is 50% or higher. Remember that there are four common atoms in molecules of the human body: hydrogen, carbon, nitrogen, and oxygen.

Hydrogen atoms, with only one electron in the 1s shell, have the smallest van der Waals radius and so they are the small, white atoms in space filling models (some artists draw them with a light blue wash). The more filled orbitals, the larger the electron cloud surrounding the nucleus, and therefore the larger the atom. Carbon, nitrogen and oxygen all have a filled 1s and 2s orbital and are in the process of filling their 2p orbital to different degrees, so they are all about the same size.
Carbon is black. Nitrogen is a bright royal blue. Oxygen is bright red.
In this Unit, you’ll see two other atoms in the space-filling representations. Sulfur is yellow. Phosphorus is orange.
Remember that nitrogen, oxygen, and sulfur have a high electronegativity and therefore tend to form polar covalent bonds within molecules and hydrogen bonds between molecules. You will want to watch for bright blue, bright red, and bright yellow in the space-filling models shown in this Unit as a visual cue that these atoms are capable of forming hydrogen bonds.
When writing complex organic molecules on paper or a computer screen, there is a shorthand way to show these where we drop the C and H atoms altogether and let you figure out where these go.
This is because carbons always form four bonds, so any time we see four lines converging on a point, we assume that point contains a C atom.
Since organic molecules, by definition, contain a good deal of carbon, this saves us time. We also drop the hydrogens, since they’re the only places we find a single bond.
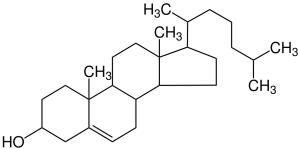
The Canvas course has a worksheet and some videos so you can see this explained (in the Learning Materials section, under Unit 3 Worksheets). There are also several formatives that will allow you to try out your newfound skills in drawing and recognizing chemical shorthand notation. It’s important because we will use shorthand and space-filling molecules from here forward and you want to be able to understand what you are seeing.
Media Attributions
- U03-001 periodic table highlight group 14 © Flowers, Paul; Theopold, Klaus; Langley, Richard; Austin, Stephen F.; Neth, Edward J. adapted by Jim Hutchins is licensed under a CC BY (Attribution) license
- U03-002.functional groups © Compound Interest is licensed under a CC BY-NC-ND (Attribution NonCommercial NoDerivatives) license
- U03-003 Ethanol_Conformer3D_large (1) © Hutchins, Jim is licensed under a Public Domain license
- U03-004 Ethanol-2D-flat.svg © Jü is licensed under a Public Domain license
- U03-005 Glycerin_Conformer3D_large © Hutchins, Jim is licensed under a Public Domain license
- U03-006 Glycerin_Skelett.svg © NEUROtiker is licensed under a Public Domain license
- U03-007 organic functional groups © Hutchins, Jim is licensed under a CC BY-SA (Attribution ShareAlike) license
- U03-008a.salicylic acid 2D line drawing © Hutchins, Jim is licensed under a Public Domain license
- U03-008b.salicylic acid 3D ball stick © Hutchins, Jim is licensed under a Public Domain license
- U03-008c.methyl salycilate 2D line drawing © Hutchins, Jim is licensed under a Public Domain license
- U03-008d.methyl salycilate 3D ball stick © Hutchins, Jim is licensed under a Public Domain license
- U03-008e.acetyl salicylic acid 2D line drawing © Hutchins, Jim is licensed under a Public Domain license
- U03-008e.acetyl salicylic acid 3D ball stick © Hutchins, Jim is licensed under a Public Domain license
- U03-009.triglyceride structure composite © Nothingserious adapted by J.D. Speth is licensed under a Public Domain license
- U03-011 same as U02-106 Dehydration_Synthesis_and_Hydrolysis-01 © Betts, J. Gordon; Young, Kelly A.; Wise, James A.; Johnson, Eddie; Poe, Brandon; Kruse, Dean H. Korol, Oksana; Johnson, Jody E.; Womble, Mark & DeSaix, Peter adapted by J.D. Speth is licensed under a CC BY-SA (Attribution ShareAlike) license
- U03-012 ouroboros © Haltopub is licensed under a CC BY-SA (Attribution ShareAlike) license
- U03-013 Building_blocks_of_life © Boghog is licensed under a CC BY-SA (Attribution ShareAlike) license
- U03-014 FDA_Nutrition_Facts_Label_2016 © FDA of the United States is licensed under a Public Domain license
- U03-015 same as U02-078a Color Key © Crookston, Alexa is licensed under a CC BY-NC-ND (Attribution NonCommercial NoDerivatives) license
- U03-016 Cholesterol_molecule_spacefill © Jynto (talk) is licensed under a CC0 (Creative Commons Zero) license
- U03-017 Cholesterol_(chemical_structure) © Wesalius is licensed under a Public Domain license

{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
.svg#/media/File:Cholesterol_(chemical_structure).svg){kind=link}