

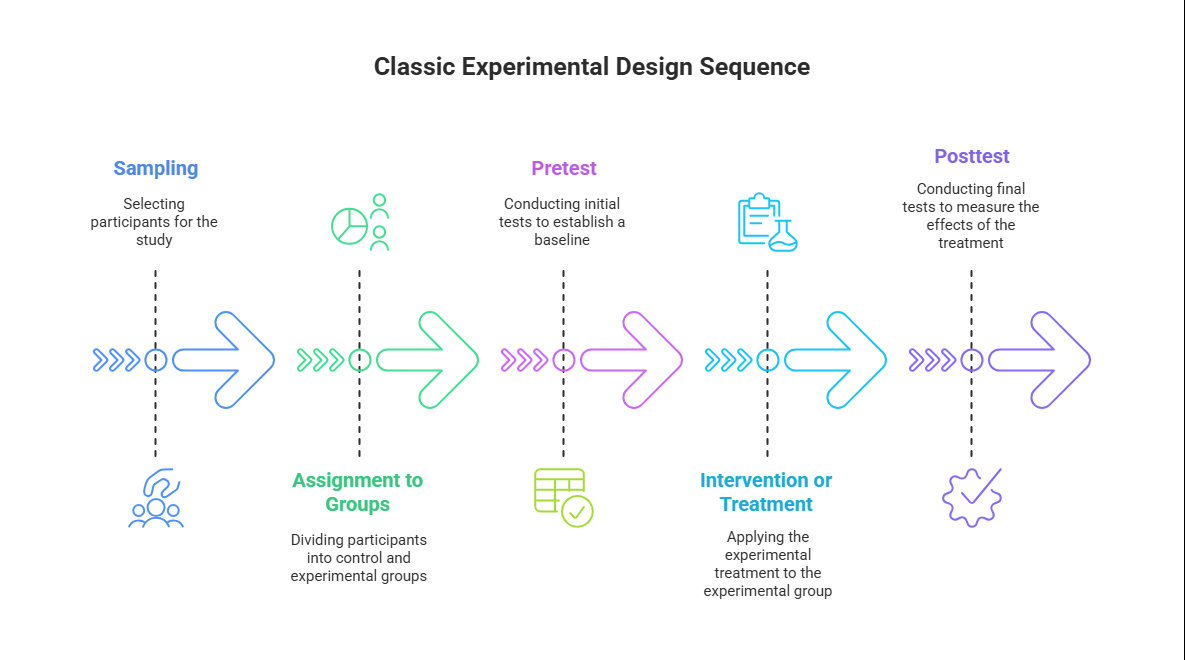
As we’ve just discussed, an experiment is a type of study designed specifically to answer the question of whether there is a causal relationship between two variables. In other words, whether changes in an independent variable cause a change in a dependent variable. Experiments have two fundamental features. The first is that the researchers manipulate, or systematically vary, the level of the independent variable. The different levels of the independent variable are called conditions. Let’s look at a specific study for an example. Pepin’s 2019 study, titled Beliefs about Money in Families: Balancing Unity, Autonomy, and Gender Equality is a great example of an experimental study that used stimuli to test the effect of certain information on beliefs. In this case, the manipulation had to do with the characteristics of a fictional couple (presented in a small story or description, called a vignette), and the outcome was how respondents felt the fictional couple should pool their money – or alternatively, if the respondents felt the couple should keep their money separate or in some combination of pooled and separate accounts. In this study, there were four independent variables, with multiple conditions in each: relationship status (with the conditions of married or cohabiting), parental status (with conditions of parents or not parents), relationship duration (3 years or 7 years), and relative earnings (equal earners, man earns more, or woman earns more). There was thus a total of 24 different scenarios that could be tested with all conditions considered; respondents each only received one scenario to rate their feelings on shared or separate money.
The second fundamental feature of an experiment is that the researcher controls, or minimizes the variability in, variables other than the independent and dependent variable. These other variables are called extraneous variables. In Pepin’s study, all respondents received the same survey in the same mode (online), with the only difference being the specific couple scenario they received, assigned randomly. Note that other details of the couple were the same for each respondent: the names of the man and woman were held steady (and by extension, the gender composition and assumed race), the ages, and the order of description was all the same for each scenario – the only differences between each vignetter were the independent variables. Notice that although the words manipulation and control have similar meanings in everyday language, researchers make a clear distinction between them. They manipulate the independent variable by systematically changing its levels and control other variables by holding them constant.
Let’s Break it Down
Show
Extraneous Variables
In simple terms:
Extraneous variables are outside factors that you’re not trying to study—but they could still affect the results if you’re not careful.
Example:
A researcher wants to know if classroom noise affects how well students do on a math test.
-
Independent variable = Level of noise in the classroom
-
Dependent variable = Test scores
But…
One group of students is being tested in the morning, and the other in the afternoon.
Or one group was tested in a room with a noxious smell and the other group didn’t have the smell in the room.
Those things—time or smell—are extraneous variables.
They aren’t part of the study, but they could still affect test scores and confuse the results.

* This image was created using ChatGPT; however, the concept, design direction, and creative vision were conceived by Dr. Knight
Dr. Christie Knight
Manipulation of the Independent Variable
Again, to manipulate an independent variable means to change its level systematically so that different groups of participants are exposed to different levels of that variable (including any vs. none if that is appropriate), or the same group of participants is exposed to different levels at different times. For example, to see whether expressive writing affects people’s health, a researcher might instruct some participants to write about traumatic experiences and others to write about neutral experiences. As discussed earlier in this chapter, the different levels of the independent variable are referred to as conditions, and researchers often give the conditions short descriptive names to make it easy to talk and write about them. In this case, the conditions might be called the “traumatic condition” and the “neutral condition.”
Notice that the manipulation of an independent variable must involve the active intervention of the researcher. Comparing groups of people who differ on the independent variable before the study begins is not the same as manipulating that variable. For example, a researcher who compares the health of people who already keep a journal with the health of people who do not keep a journal has not manipulated this variable and therefore has not conducted an experiment. This distinction is important because groups that already differ in one way at the beginning of a study are likely to differ in other ways too. For example, people who choose to keep journals might also be more conscientious, more introverted, or less stressed than people who do not. Therefore, any observed difference between the two groups in terms of their health might have been caused by whether or not they keep a journal, or it might have been caused by any of the other differences between people who do and do not keep journals. Thus, the active manipulation of the independent variable is crucial for eliminating potential alternative explanations for the results.
Of course, there are many situations in which the independent variable cannot be manipulated for practical or ethical reasons and therefore an experiment is not possible. For example, whether or not people have a significant early illness experience cannot be manipulated, making it impossible to conduct an experiment on the effect of early illness experiences on the development of hypochondriasis. This caveat does not mean it is impossible to study the relationship between early illness experiences and hypochondriasis—only that it must be done using nonexperimental approaches.
Independent variables can be manipulated to create two conditions and experiments involving a single independent variable with two conditions is often referred to as a single factor two-level design. However, sometimes greater insights can be gained by adding more conditions to an experiment. When an experiment has one independent variable that is manipulated to produce more than two conditions it is referred to as a single factor multi level design. If even more variables are added, we can begin to write out the design by providing the number of conditions for each independent variable. In the example above from Pepin (2019), we would call this a 2 x 2 x 2 x 3 factorial design, because it had four independent variables, the first three of which had two conditions, and the fourth of which had three conditions.
Control of Extraneous Variables
As we have seen previously, an extraneous variable is anything that varies in the context of a study other than the independent and dependent variables. In an experiment on the effect of expressive writing on health, for example, extraneous variables would include participant variables (individual differences) such as their writing ability, their diet, and their gender. They would also include situational or task variables such as the time of day when participants write, whether they write by hand or on a computer, and the weather. Extraneous variables pose a problem because many of them are likely to have some effect on the dependent variable. For example, participants’ health will be affected by many things other than whether or not they engage in expressive writing. This influencing factor can make it difficult to separate the effect of the independent variable from the effects of the extraneous variables, which is why it is important to control extraneous variables by holding them constant whenever possible, and by randomizing groups so that variables that cannot be directly controlled can be distributed.
Extraneous variables make it difficult to detect the effect of the independent variable in two ways. One is by adding variability or “noise” to the data. Imagine a simple experiment on the effect of mood (happy vs. sad) on the number of happy childhood events people are able to recall. Participants are put into a negative or positive mood (by showing them a happy or sad video clip) and then asked to recall as many happy childhood events as they can. The two leftmost columns of the Table below show what the data might look like if there were no extraneous variables and the number of happy childhood events participants recalled was affected only by their moods. Every participant in the happy mood condition recalled exactly four happy childhood events, and every participant in the sad mood condition recalled exactly three. The effect of mood here is quite obvious. In reality, however, the data would probably look more like those in the two rightmost columns of the Table. Even in the happy mood condition, some participants would recall fewer happy memories because they have fewer to draw on, use less effective recall strategies, or are less motivated. And even in the sad mood condition, some participants would recall more happy childhood memories because they have more happy memories to draw on, they use more effective recall strategies, or they are more motivated. Although the mean difference between the two groups is the same as in the idealized data, this difference is much less obvious in the context of the greater variability in the data. Thus one reason researchers try to control extraneous variables is so their data look more like the idealized data in Table 5.1, which makes the effect of the independent variable easier to detect (although real data never look quite that good).
| Idealized “noiseless” data | Realistic “noisy” data | ||
| Happy mood | Sad mood | Happy mood | Sad mood |
| 4 | 3 | 3 | 1 |
| 4 | 3 | 6 | 3 |
| 4 | 3 | 2 | 4 |
| 4 | 3 | 4 | 0 |
| 4 | 3 | 5 | 5 |
| 4 | 3 | 2 | 7 |
| 4 | 3 | 3 | 2 |
| 4 | 3 | 1 | 5 |
| 4 | 3 | 6 | 1 |
| 4 | 3 | 8 | 2 |
| M = 4 | M = 3 | M = 4 | M = 3 |
One way to control extraneous variables is to hold them constant. This technique can mean holding situation or task variables constant by testing all participants in the same location, giving them identical instructions, treating them in the same way, and so on. It can also mean holding participant variables constant. For example, many studies of language limit participants to right-handed people, who generally have their language areas isolated in their left cerebral hemispheres. Left-handed people are more likely to have their language areas isolated in their right cerebral hemispheres or distributed across both hemispheres, which can change the way they process language and thereby add noise to the data.
In principle, researchers can also control extraneous variables by limiting participants to one very specific category of person, such as 20-year-old, heterosexual, female, right-handed psychology majors. The obvious downside to this approach is that it would lower the external validity of the study—in particular, the extent to which the results can be generalized beyond the people actually studied. For example, it might be unclear whether results obtained with a sample of younger heterosexual women would apply to older homosexual men. In many situations, the advantages of a diverse sample (increased external validity) outweigh the reduction in noise achieved by a homogeneous one.
The second way that extraneous variables can make it difficult to detect the effect of the independent variable is by becoming confounding variables. A confounding variable is an extraneous variable that differs on average across levels of the independent variable (i.e., it is an extraneous variable that varies systematically with the independent variable). For example, in almost all experiments, participants’ intelligence quotients (IQs) will be an extraneous variable. But as long as there are participants with lower and higher IQs in each condition so that the average IQ is roughly equal across the conditions, then this variation is probably acceptable (and may even be desirable). What would be bad, however, would be for participants in one condition to have substantially lower IQs on average and participants in another condition to have substantially higher IQs on average. In this case, IQ would be a confounding variable.
Let’s Break it Down
Show
Confounding Variable
In simple terms:
A confounding variable is something extra that affects both the cause and the effect you’re studying. It makes it hard to tell if the results are really caused by the factor you’re testing, or by this other hidden factor.
Example:
A researcher wants to study if screen time (how much time teens spend on phones or computers) affects their grades.
-
Independent variable = Screen time
-
Dependent variable = Academic performance (grades)
But… what if students who spend more time on screens also sleep less?
Now the researcher can’t tell if bad grades are due to screen time or because the students are tired from lack of sleep.
In this case, sleep is a confounding variable—it’s linked to both screen time and grades, and it could be the real reason for the drop in performance.
* This image was created using ChatGPT; however, the concept, design direction, and creative vision were conceived by Dr. Knight
Dr. Christie Knight
To confound means to confuse, and this effect is exactly why confounding variables are undesirable. Because they differ systematically across conditions—just like the independent variable—they provide an alternative explanation for any observed difference in the dependent variable. Above, we talked about a hypothetical study in which participants in a positive mood condition scored higher on a memory task than participants in a negative mood condition. But if IQ is a confounding variable—with participants in the positive mood condition having higher IQs on average than participants in the negative mood condition—then it is unclear whether it was the positive moods or the higher IQs that caused participants in the first condition to score higher. One way to avoid confounding variables is by holding extraneous variables constant. For example, one could prevent IQ from becoming a confounding variable by limiting participants only to those with IQs of exactly 100. But this approach is not always desirable for reasons we have already discussed. A second and much more general approach—random assignment to conditions—will be discussed in detail shortly.
Mediating and Moderating Variables
In addition to confounding and extraneous variables, researchers must also be familiar with two other major types of variables that can influence the study’s outcome: mediating and moderating variables. These variables are not directly responsible for changing the dependent variable, but they help describe or shape the relationship between the independent and dependent variables in meaningful ways.
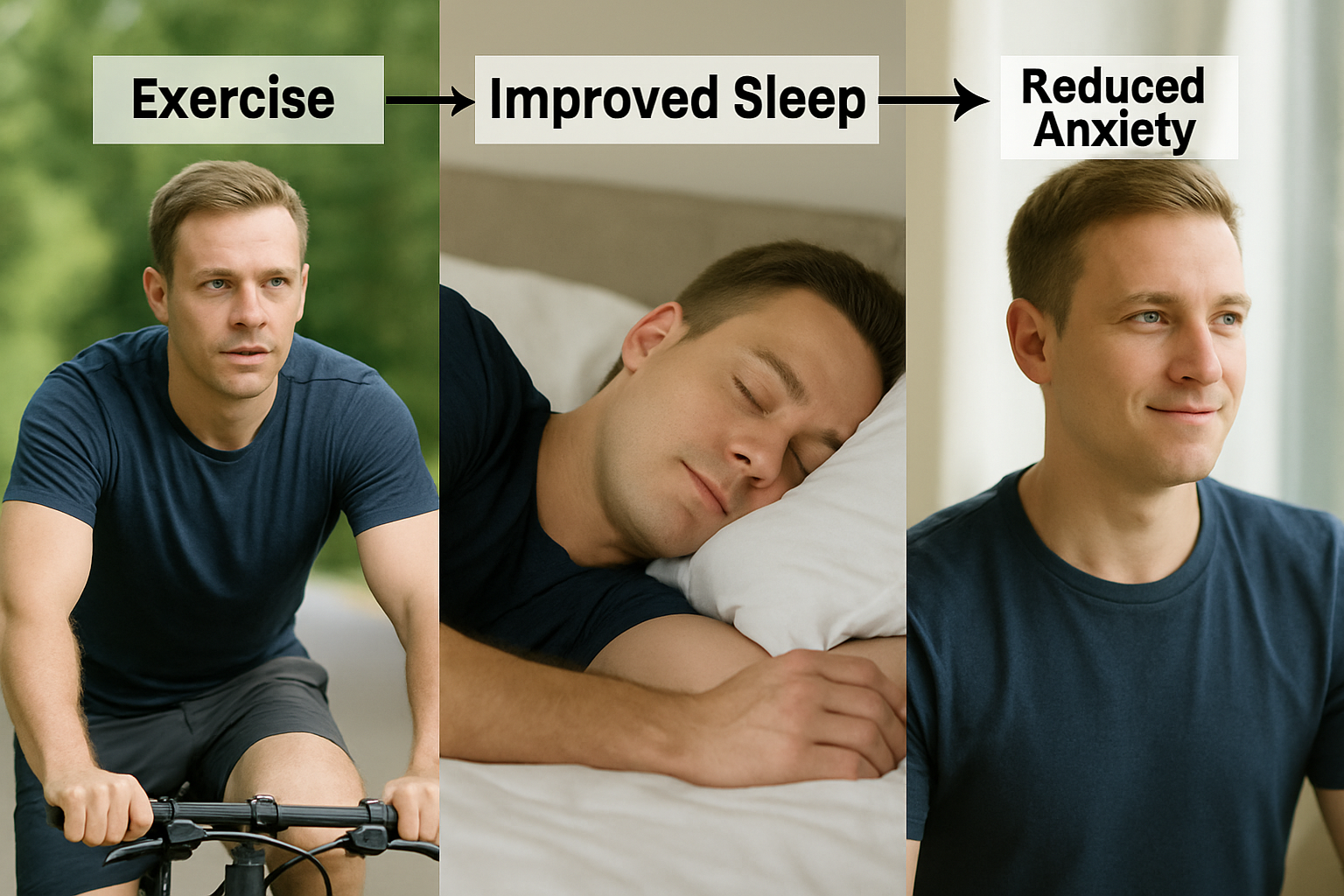
A mediating variable, also known as an intervening variable, helps explain how or why an independent variable (X) influences a dependent variable (Y). It acts as a link in the middle of the cause-and-effect chain, showing the process that connects X to Y. In other words, it tells us what happens in between that helps carry the effect from one variable to the other. Mediating variables are essential for understanding the underlying mechanisms of a relationship, offering insight into the steps or changes that occur between the cause and its outcome. This deeper understanding can improve the accuracy of conclusions drawn from the research and guide more effective interventions. For example, in examining whether exercise reduces anxiety, improved sleep could be a mediating variable. In this case, exercise leads to better sleep, and better sleep then reduces anxiety. Mediators help answer the “how” or “why” behind a causal connection between variables.
Let’s Break it Down- An Example
Show
Mediating Variable
For example, let’s say a study is exploring whether exercise can help reduce anxiety. In this case, improved sleep might be a mediating variable. Exercise may not directly lower anxiety, but it can lead to better sleep, and that improved sleep can then help reduce anxiety. So, better sleep explains how exercise has a calming effect. This illustrates how a mediator helps uncover the underlying process behind the connection, providing a clearer understanding of the relationship between the variables.
 *This image was created using ChatGPT; however, the concept, design direction, and creative vision were conceived by Dr. Knight
*This image was created using ChatGPT; however, the concept, design direction, and creative vision were conceived by Dr. Knight
Dr. Christie Knight
A moderating variable, or effect modifier, changes the direction or strength of the relationship between an independent and a dependent variable. It acts as a “condition” that influences the degree to which the relationship holds true. In other words, the effect of one variable on another depends on the presence or level of the moderator. The impact of the IV on the DV depends on the level of the moderator.
Let’s Break it down-Example
Moderating Variable
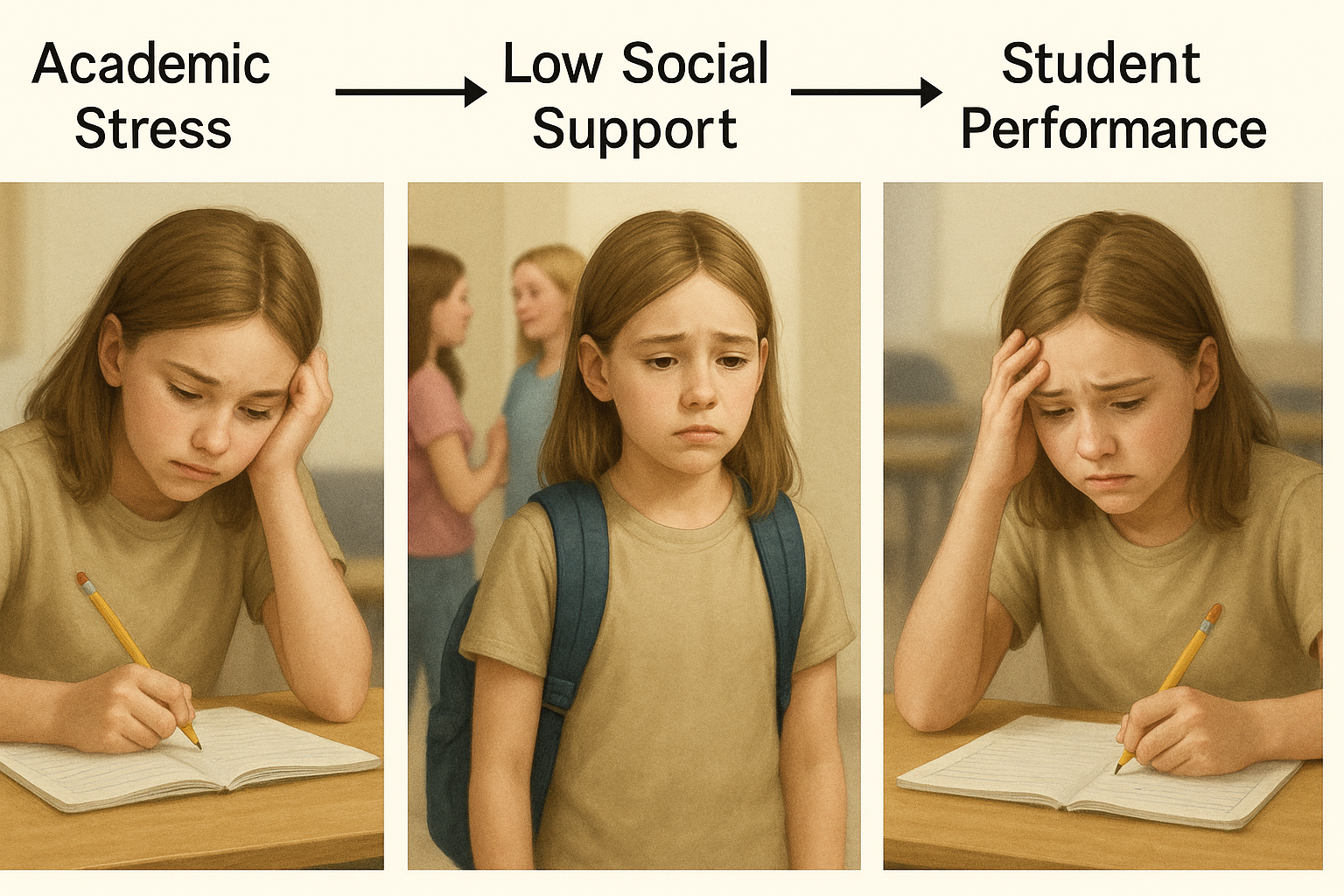
For example, if the independent variable is academic stress, and the dependent variable is student performance, a moderating variable could social support—it could change how much academic stress affects student performance depending on how much social support a student feels.
➤ With High Social Support
Even though the student is experiencing academic stress, having supportive peers helps buffer the negative effects. The student remains emotionally balanced and performs well.
Academic Stress → Social Support → Strong Student Performance

*This image was created using ChatGPT; however, the concept, design direction, and creative vision were conceived by Dr. Knight
➤ With Low Social Support
The same level of academic stress has a stronger negative effect when the student feels isolated. With little or no support from peers, the student struggles more and performance drops.
Academic Stress → Low Social Support → Struggling Performance]
*This image was created using ChatGPT; however, the concept, design direction, and creative vision were conceived by Dr. Knight
Dr.Christie Knight
