The Purpose of Sampling
Population, Census, and Sample
In social scientific research, a population of interest is the cluster of people you are most interested in; it is often the “who” that you want to be able to say something about at the end of your study. Populations in research may be rather large, such as “the American people,” but they are typically more specific. For example, a large study interested in the population of the American people will likely specify which American people, such as adults over the age of 18, citizens, or legal permanent residents.
It is quite rare for a researcher to gather data from their entire population of interest. If a research study is able to collect data from every single member of the given population, this is called a census. You’ve probably heard of the U.S. Census. This is a decennial collection effort, meaning it takes place every 10 years, in which the goal is to collect a small amount of information from every person in the United States. Censuses happen in other countries, of course, and in other data collection efforts, but because the goal is to get data from every single member of the population, this is challenging and resource-intensive. As such, most research does not use census methods for sampling and thus cannot study every member. This might sound surprising or disappointing until you think about the kinds of research questions that social scientists typically ask. For example, let’s say we wish to answer the following research question: “How is participation in a premarital education program associated with later divorce risk?” Would you expect to be able to collect data from all people in premarital education programs across all nations from all historical time periods? Unless you plan to make answering this research question your entire life’s work (and then some), the answer is likely a resounding no. So, what to do? Does the lack of time or resources to gather data from every single person of interest mean that you must give up your research interest?
Examples
Show
Targeting the Right Group: Using AI to Help Identify Your Research Population
How AI Can Help Define the Population of Interest?
When you start a research project, one of the first things you need to figure out is who you’re studying—this is called your population of interest or your target population. For example, if you’re researching anxiety levels in college students, do you mean all college students? Just freshmen? Only students in a specific major?
AI can make this process easier by looking at past research to suggest who might be the best group to study. Here’s how:
- Looking at Demographics (Who they are?)
- AI can analyze factors such as age, gender, income level, or education to help you narrow down your target population.
- Example: Imagine you are researching how parental involvement affects the academic success and well-being of first-generation college students.
AI might find that:
- First-generation college students from low-income families face unique academic and emotional challenges.
- AI might suggest focusing on this specific group rather than all college students in a study on parental involvement in higher education.
- Considering Geography (Where They Live)
- AI can check if location matters for your study.
- Example: Imagine you’re researching the impact of grandparent involvement on child development.
AI might find that:
-
-
- Multigenerational households are more common in rural areas, meaning grandparents may play a more significant role in childcare and discipline.
- Families may rely more on daycare and external childcare services in urban areas, leading to different child-rearing practices.
- AI might suggest focusing on households in rural areas.
-
- Psychographics (How They Think and Behave)
- AI can also analyze people’s interests, values, or lifestyle choices.
- Example: If you’re researching how family mealtime habits impact parent-child communication.
AI might find that:
-
-
- Families who prioritize shared meals and conversation tend to have stronger parent-child relationships.
- Families who eat separately or in front of screens may experience fewer meaningful interactions.
- AI might suggest studying families who regularly eat together vs. those who don’t to explore how mealtime routines affect family bonding and communication skills.
-
Instead of guessing who you should study, AI can look at real data and give smart suggestions, helping you focus on the most relevant group.
Elicit.org is an AI tool that can help define a target population for research. Here’s how it works and how it can assist in refining your sample selection.
What It Does:
Elicit is an AI-powered research assistant that helps find academic papers, summarize findings, and suggest relevant variables for your study. It can assist in defining a target population by analyzing existing literature and identifying trends in past studies. Let me take you through a specific example to demonstrate how Elicit.org can be used to identify an appropriate target population.
For this example, let’s use the research question:
“How does social media impact body image in teenagers?”
How Elicit Helps:
- Finds existing studies on social media and body image.
- Identifies patterns (e.g., Most studies focus on girls aged 13-17, but fewer on boys or nonbinary teens).
- Suggests refining the population (e.g., Maybe focus on teen athletes or teens who follow fitness influencers).
- Recommends key variables (e.g., Instagram usage time, self-esteem scores, frequency of comparison behaviors).
Here’s a step-by-step walkthrough on how to use Elicit.org to define a target population for a research project.
- Open your web browser and go to https://elicit.org. (You may need to create an account, but basic features are free.)
- In the search bar, type your research question. Elicit will search academic papers and provide a summary of findings.
- Once Elicit pulls up results, you can begin to look for patterns.
For example, if we type in our research question: “How does social media impact body image in teenagers?”, we might look for the following patterns:
Demographics (Who was studied?)
-
-
- Are past studies focused on a certain age range?
- Are studies primarily done on girls, boys, or a mix?
-
Geographic Focus (Where were participants from?)
-
-
- Were studies conducted in specific countries or urban/rural settings?
-
Psychographic Traits (What characteristics define them?)
-
-
- Are participants athletes, social media influencers, students, etc.?
- Are there any behavioral traits mentioned (e.g., high vs. low social media users)?
-
- You can look for gaps in the literature.If Elicit shows most studies focus on girls aged 13-17, you might decide:
-
-
- To confirm that group as your target population.
- OR, to explore a missing population (e.g., boys, nonbinary teens, or younger children).
-
If most studies only focus on Instagram, you might decide to explore:
-
-
-
- TikTok, Snapchat, or newer platforms.
-
-
- You can then refine your inclusion and exclusion criteria.
Now that you know who has been studied, you can define:
- Who you will include (inclusion criteria) in your study- Teens aged 13-18 who use Instagram at least 1 hour per day.
- Who you will exclude (exclusion criteria) – Teens who do not use social media at all.
Other AI Tools That Can Help
- ChatGPT – Helps brainstorm target populations based on logical reasoning.
- Google Dataset Search – Finds public datasets on different populations.
- Pew Research Data Explorer – Shows trends on different demographics.
Dr. Christie Knight

The nursing home example is perhaps an easy one. Let’s consider some more examples. Unlike nursing home patients, cancer survivors do not live in an enclosed location and may no longer receive treatment at a hospital or clinic. For researchers to reach participants, they may consider partnering with a support group that services this population. Perhaps there is a support group at a local church in which survivors may cycle in and out based on need. Without a set list of people, the sampling frame would simply be the people who showed up to the support group on the nights the researchers were there, which is a hypothetical list.
Another example population are homeless. More challenging still is recruiting people who are homeless, those with very low income, or people who belong to stigmatized groups. For example, a research study by Johnson and Johnson (2014) attempted to learn usage patterns of “bath salts,” or synthetic stimulants that are marketed as “legal highs.” Users of “bath salts” don’t often gather for meetings, and reaching out to individual treatment centers is unlikely to produce enough participants for a study as use of bath salts is rare. To reach participants, these researchers ingeniously used online discussion boards in which users of these drugs share information. Their sampling frame included everyone who participated in the online discussion boards during the time they collected data. Regardless of whether a sampling frame is easy or challenging, the first rule of sampling is: go where your participants are.
Once you have an idea of where your participants are, you need to recruit your participants into your study. Recruitment refers to the process by which the researcher informs potential participants about the study and attempts to get them to participate. Recruitment comes in many different forms. If you have ever received a phone call asking for you to participate in a survey, someone has attempted to recruit you for their study. Perhaps you’ve seen print advertisements on buses, in student centers, or in a periodical. As we learn more about specific types of sampling, make sure your recruitment strategy makes sense with your sampling approach. For example, if you put up a flyer in the student health office to recruit for your study, you would likely be using availability or convenience sampling, which differ in key ways from methods like random sampling.

As you think about sampling frame and recruitment, another level of specificity that researchers add at this stage is deciding if there are certain characteristics or attributes that individuals must have if they participate in your study. These are known as inclusion and exclusion criteria. Inclusion criteria are the characteristics a person must possess in order to be included in your sample. If you were conducting a survey on centenarians living in nursing homes, you might want to sample only elderly adults. In that case, your inclusion criteria for your sample would be that individuals have to be age 100 or older and they must be actively living in a nursing home. Comparably, exclusion criteria are characteristics that disqualify a person from being included in your sample. Going back to the previous example, an older adult could be excluded from your sample because they are 99 years or younger, or because they do not actively live in a nursing home. Exclusion criteria are often like the mirror image of inclusion criteria. However, there may be other criteria by which you want to exclude people from your sample. For example, you may exclude centenarians who are in a medically vegetative state or centenarians who have not lived at the nursing home more than 30 days.
Let’s Break it Down
Show
Inclusion Criteria
In simple terms:
Inclusion criteria are the rules researchers use to decide who can participate in a study. These rules ensure that the participants are the right fit for the topic.
That way, the results can actually tell us something useful about the group we’re trying to learn about.
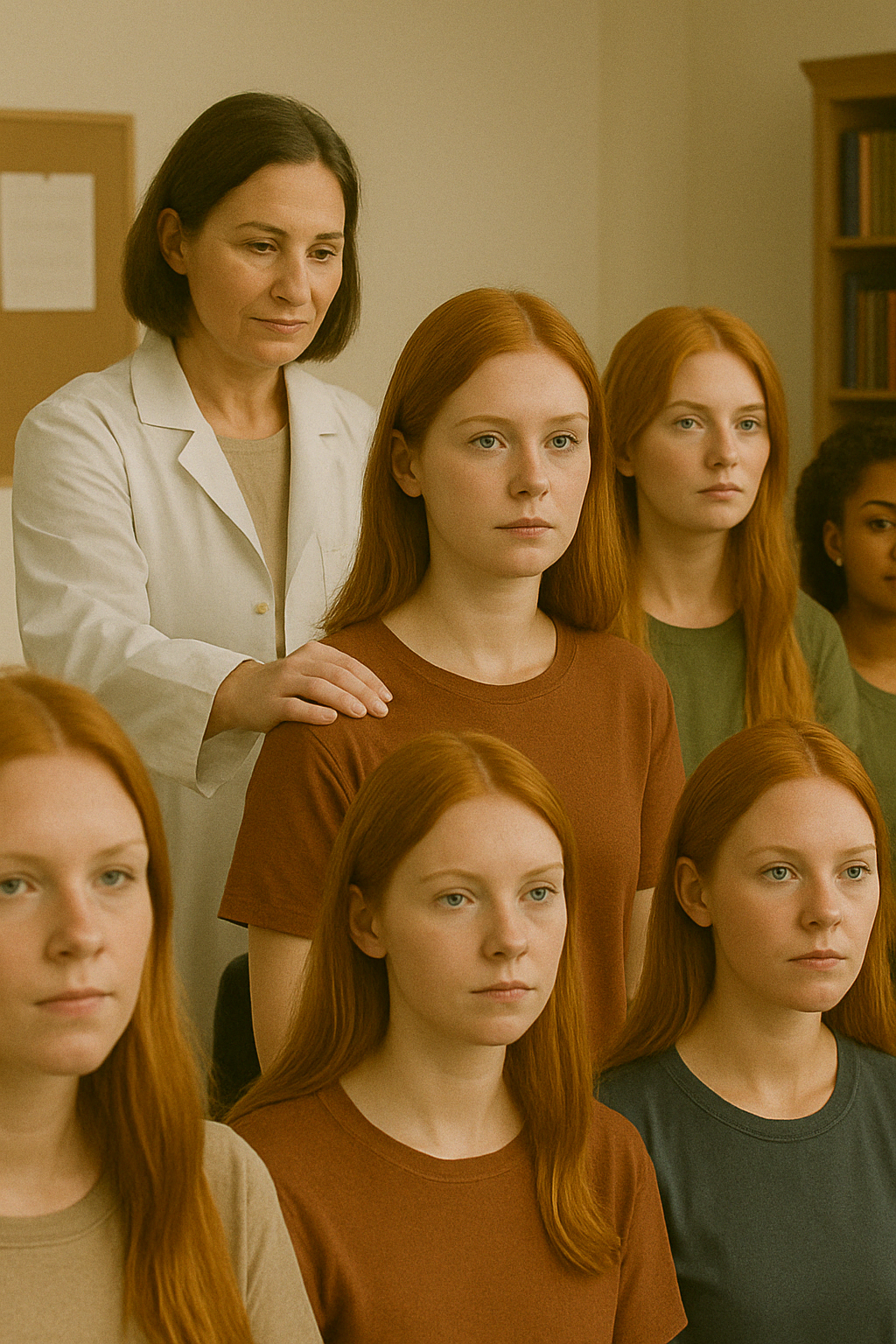
* This image was created using ChatGPT; however, the concept, design direction, and creative vision were conceived by Dr. Knight
Example:
Let’s say you’re studying stress in red-headed college students who work part-time.
Your inclusion criteria might be:
- Must be a college student
- Must have a part-time job
- Must have red hair
Only people who meet all three rules can be in the study.
Dr. Christie Knight
Let’s Break it Down
Show
Exclusion Criteria
In simple terms:
Exclusion criteria are the rules that remove people from a study.
These rules help keep the study focused and avoid factors that might affect the results.

* This image was created using ChatGPT; however, the concept, design direction, and creative vision were conceived by Dr. Knight
Example:
In a study about how glasses affect reading speed, people who don’t wear glasses will be excluded—even if they’re the right age and they read daily. Anyone who doesn’t wear glasses will be asked to leave and/or not participate in the study, because they don’t fit the purpose of the study.
Dr. Christie Knight
When defining inclusion and exclusion criteria, think about the ethical principle of justice that we talked about back in Chapter 4. Justice requires that we consider how risks and benefits are distributed among the population. As you think about who should and should not participate in your study, be prepared to justify your decisions. Limiting your study of marital satisfaction to married couples makes sense. However, do you need to limit it to only different-sex couples, though, or are you interested in all married couples regardless of gender composition? Unintentional exclusion can be a risk if you’re not careful about how you recruit – continuing this example of married couples, if you are open to including both same- and different-gendered couples in your study but your recruitment flyers all have a picture of a man and woman in a tux and a white dress, you’ll likely exclude same-sex couples without meaning to, which can bias your study.
Once you recruit your participants and enroll them in your study, you end up with a sample. If you are a participant in a research project—answering survey questions, participating in interviews, etc.—you are part of the sample of that research project. Some social science research projects may not use people at all. Instead of people, the elements selected for inclusion into a sample are documents, including [such as] client records, blog entries, or television shows. A researcher conducting this kind of analysis, described later in the book, would still go through the stages of sampling—identifying a sampling frame or accessible population, applying inclusion criteria, and gathering the sample–but it will of course look different (and different ethical considerations will be considered).
Vulnerable Populations
When thinking about who you want to study, you must consider if your population of interest or the sample you’ll take will include vulnerable populations. Vulnerable populations can include children (minors), pregnant people, prisoners, those with cognitive impairments or physical disabilities, and others depending on their ability to give informed consent for participation in research.
If you desire to work with vulnerable populations in a research study, there are special considerations that the IRB will often require you to detail and often special procedures you might need to follow (like getting both consent from a guardian and assent from children or teenagers participating in your study).
Sometimes, you’re not specifically aiming to work with a vulnerable population, but they end up in your study – for example, you’re doing a survey about media consumption and your population of interest is young adults in Utah. In your sample of 18-29-year-olds you could end up with some pregnant women. That’s usually not a big concern. In this study, because you’re not focused on pregnant women or doing anything that would put them at extra risk because of being pregnant, there’s probably not an undue risk for them being in your study and you wouldn’t need to exclude them or provide anything different for them. However, you’d still do well to note the potentiality in your study design and in your application to the IRB, since pregnancy can make someone “vulnerable” to risks in research.
Even if they’re not one of the groups mentioned above, there may be other reasons to consider your population of interest to be “vulnerable” and deserving of extra protection in your research. Perhaps you want to study homeless individuals, parents with children in the hospital, or recent widows. These and other vulnerable individuals deserve to have research done about their experiences and needs, so don’t just assume that we shouldn’t study vulnerable people, but do be prepared to take precautions and build in protections that may be even more extensive than those already required for basic human research.
Unit of Analysis
Before we jump into types of sampling, we should also consider the unit of observation that we’ll be focusing on, and how our later analysis will depend on decisions we make about sampling. It is imperative to consider units of analysis and units of observation. These may differ slightly in quantitative and qualitative research designs. These two items concern what the researcher observes in their data collection and what they hope to say about those observations. A unit of analysis is the entity that you wish to say something about at the end of your study, and it is considered the focus of your study. A unit of observation is the item (or items) that you observe, measure, or collect while trying to learn something about your unit of analysis.
In some studies, the unit of observation may be the same as the unit of analysis. For example, a study on electronic gadget addiction may interview undergraduate students (our unit of observation) for the purpose of saying something about undergraduate students (our unit of analysis) and their gadget addiction. Perhaps, if we were investigating gadget addiction in elementary school children (our unit of analysis), we might collect observations from teachers and parents (our units of observation) because younger children may not report their behavior accurately. In this case and many others, units of analysis are not the same as units of observation. However, researchers are required to clearly define their units of analysis and units of observation to themselves and their audiences.
More specifically, your unit of analysis will be determined by your research question. Your unit of observation, on the other hand, is determined largely by the method of data collection that you use to answer that research question. We’ll take a closer look at methods of data collection later on in the textbook. For now, let’s consider our previous example study that sought to address students’ addictions to electronic gadgets. We’ll consider first how different types of research questions about this topic may yield different units of analysis. Then, we’ll think about how those questions might be answered and with what kinds of data. This leads us to a variety of units of observation.
Let’s say that we are going to explore which students are most likely to be addicted to their electronic gadgets. Our unit of analysis would be the individual students. We would likely email a survey to students on campus. We would classify individuals based on social group membership to see how membership in certain specific social groups correlates with electronic gadget addiction. For example, we might find that students majoring in new media, students that identify as men, and students with high socioeconomic status are more likely than other students to become addicted to their electronic gadgets. We could also explore how students’ gadget addictions differ and how are they similar. In this case, we could conduct observations of addicted students and record when, where, why, and how they use their gadgets. Whether the information about students’ addictions to electronic gadgets is collected by survey response or by direct observation, data are collected from individual students. Thus, the unit of observation in both examples is the individual.
Another common unit of analysis in social science inquiry is the group. Of course, groups vary in size, but almost no group is too small or too large to be of interest to social scientists. Families, friendship groups, and group therapy participants are some common examples of micro-level groups examined by social scientists. Employees in an organization, professionals in a particular domain (e.g., chefs, lawyers, social workers), and members of clubs (e.g., Girl Scouts, Rotary, Red Hat Society) are all meso-level groups that social scientists might study. Finally, at the macro-level, social scientists sometimes examine citizens of entire nations or residents of different continents or other regions.
A study of student addictions to their electronic gadgets at the group level might consider whether certain types of social clubs have more or fewer gadget-addicted members than other sorts of clubs. Perhaps we would find physical fitness clubs, such as the rugby club and the scuba club, have fewer gadget-addicted members than cerebral activity clubs, like the chess club and the women’s studies club. Our unit of analysis in this example is groups because groups are what we hope to say something about. If we had asked whether individuals who join cerebral clubs are more likely to be gadget-addicted than those who join social clubs, then our unit of analysis would have been individuals. In either case, however, our unit of observation would be individuals.
Organizations are yet another potential unit of analysis that social scientists might wish to say something about. Organizations include entities like corporations, colleges and universities, and even nightclubs. At the organization level, a study of students’ electronic gadget addictions might explore how different colleges address this social issue. In this case, our interest lies not in the experience of individual students but instead in the campus-to-campus differences in confronting gadget addictions. A researcher conducting a study of this type might examine schools’ written policies and procedures, so their unit of observation would be documents. However, because they ultimately wish to describe differences across campuses, the college would be their unit of analysis.
In sum, there are many potential units of analysis that a social worker might examine, but some of the most common units include the following:
- Individuals
- Groups
- Organizations
| Research question | Unit of analysis | Data collection | Unit of observation | Statement of findings |
| Which students are most likely to be addicted to their electronic gadgets? | Individuals | Survey of students on campus | Individuals | New Media majors, men, and students with high socioeconomic status are all more likely than other students to become addicted to their electronic gadgets. |
| Do certain types of social clubs have more gadget-addicted members than other sorts of clubs? | Groups | Survey of students on campus | Individuals | Clubs with a scholarly focus, such as social work club and the math club, have more gadget-addicted members than clubs with a social focus, such as the 100-bottles-of- beer-on-the-wall club and the knitting club. |
| How do different colleges address the problem of electronic gadget addiction? | Organizations | Content analysis of policies | Documents | Campuses without strong computer science programs are more likely than those with such programs to expel students who have been found to have addictions to their electronic gadgets. |
| Note: Please remember that the findings described here are hypothetical. There is no reason to think that any of the hypothetical findings described here would actually bear out if tested with empirical research. | ||||
One common error people make when it comes to both causality and units of analysis is something called the ecological fallacy. This occurs when claims about one lower-level unit of analysis are made based on data from some higher-level unit of analysis. In many cases, this occurs when claims are made about individuals, but only group-level data have been gathered. For example, we might want to understand whether electronic gadget addictions are more common on certain campuses than others. Perhaps different campuses around the country have provided us with their campus percentage of gadget-addicted students, and we learn from these data that electronic gadget addictions are more common on campuses that have business programs than on campuses without them. We then conclude that business students are more likely than non-business students to become addicted to their electronic gadgets. However, this would be an inappropriate conclusion to draw. We only have addiction rates by campus, so we can only draw conclusions about campuses, not about the individual students on those campuses. Perhaps the social work majors on the business campuses are the ones that caused the addiction rates on those campuses to be so high. The point is we simply don’t know because we only have campus-level data. Therefore, we run the risk of committing the ecological fallacy if we draw conclusions about students when our data are about the campus.
In addition, another mistake to be aware of it reductionism. Reductionism occurs when claims about some higher-level unit of analysis are made based on data from some lower-level unit of analysis. In this case, claims about groups or macro-level phenomena are made based on individual-level data. An example of reductionism can be seen in some descriptions of the civil rights movement. On occasion, people have proclaimed that Rosa Parks started the civil rights movement in the United States by refusing to give up her seat to a White person while on a city bus in Montgomery, Alabama, in December 1955. Although Parks played an invaluable role in the movement and her act of civil disobedience inspired courage in others, it would be reductionist to credit her with starting the movement. Surely, many factors contributed to the rise and success of the American civil rights movement, including legalized racial segregation, the historic 1954 Supreme Court decision to desegregate schools, and the creation of the Student Nonviolent Coordinating Committee to name a few. In other words, the movement is attributable to many factors—some social, others political and others economic. Rosa Parks played a very important role in this development in American history, but to say that she caused the entire civil rights movement would be reductionist.
The preceding discussion was not meant to deter you from making claims about data or relationships between levels of analysis. While it is important to be attentive to the possibility for error in causal reasoning about different levels of analysis, this warning should not prevent you from drawing well-reasoned analytic conclusions from your data. The point is to be cautious and conscientious in making conclusions between levels of analysis. Errors in analysis stem from a lack of rigor and deviation from the scientific method.
References
Johnson, P. S., & Johnson, M. W. (2014). Investigation of “bath salts” use patterns within an online sample of users in the United States. Journal of Psychoactive Drugs, 46(5), 369-378. ↵Johnson, P. S., & Johnson, M. W. (2014). Investigation of “bath salts” use patterns within an online sample of users in the United States. Journal of Psychoactive Drugs, 46(5), 369-378. ↵
Image attributions
job interview by styles66 CC-0
Binoculars by nightowl CC-0
